白话算法(4) 谁升起,谁就是太阳
正如优秀文学的秘密并不会因为《哈姆雷特》或《曼斯菲尔德庄园》的存在而一劳永逸地昭然若揭,建筑大师奥托·瓦格纳或西古德·列维伦茨的作品也丝毫无力减少低劣建筑的增生。艺术的杰作至今仍像是凭运气偶然产生的,而艺术家仍然像成功点燃了一把火的洞穴人,并没有搞清楚他们是如何做到的,更遑论将他们取得的成就的原理讲与他人知晓了。艺术天分就像是一场绝妙的焰火,瞬间穿透漆黑的暗夜,使观者油然而生敬畏之情,可转眼间就烟消云散,只留下无尽的黑暗与向往。
——阿兰·德波顿 《幸福的建筑》选择排序
选择排序的思路是,每次从输入的数组s中拿出一个最小的元素x,放到数组L的尾部,这样一直迭代下去,直到把s掏空时,L就是排好序的s。
view sourceprint?01 static void SelectionSort(int[] s)
02 {
03 // 有序数组 L = s[0..i]
04 for (int i = 0; i < s.Length-1; i++)
05 {
06 int min = FindMin(s, i, s.Length-1);
07 swap(s, i, min);
08 }
09 }
10
11 // 返回 s[startIndex..endIndex] 里最小元素的下标
12 static int FindMin(int[] s, int startIndex, int endIndex)
13 {
14 int min = startIndex;
15 for (int j = startIndex+1; j <= endIndex; j++)
16 {
17 if (s[min] > s[j])
18 min = j;
19 }
20 return min;
21 }
22
23 // 交换 s[i] 和 s[j] 的值
24 static void swap(int[] s, int i, int j)
25 {
26 int temp = s[i];
27 s[i] = s[j];
28 s[j] = temp;
29 }
虽然这个思路看上去如此的简单直接、不言自明,但是我们心中仍然充满了疑惑。在选择排序里,有序的部分是增量的,但是,它和插入排序相比似乎又有很大的不同。它们有哪些相同和不同之处?如果它们有根本上的差别,那么这个算法是否也揭示了某种有代表性的思路呢?
这些问题很难回答,因为要怎么样才叫“增量法”,以及要有多大差别才算是“根本上”的,很难找到一个明确的定义。让我们先从可以确定的部分开始。
选择排序要求在排序之前所有的输入项目均已出现(而且它顺序地逐个产生最后的输出),而插入排序没有这个限制。从这个差别我们可以发现,对于插入排序,我们只需要关心一个系统——那个有序的子数组L,它可以接受任何随机的输入,并保持自身的有序。对于选择排序,我们必须关心两个系统——有序的系统L=s[0..i]和无序的系统R=s[i+1..n-1],可以认为L是增量的(它每次接收一个元素,并且保持有序),只是它要求每次输入的元素必须比系统内的所有元素都要大,这就要求必须要有一个“每次输出一个更大的元素的系统”R。每次迭代,系统R的输出正好就是系统L所需要的输入。在看过前面3篇之后,对于如何处理增量的系统L我们已经很熟悉了,我们比较陌生的,是对“递减”的系统R的处理方法。每次从系统R中拿出一个最小的元素,就可确保每次从R中拿出来的元素都比前一次的大,这个逻辑虽然简单,但是也只有人类才能想出来并且理解它吧。选择排序的性能
选择排序的最坏情况时间代价为Θ(n2)。这是因为R是无序的,所以要找到最小的元素就必须把R中所有元素都遍历一遍。要想提高性能,自然是要把R先搞成某种有序(这个“有序”指的不是“有顺序”而是指“有一定规律”)的形式,籍此来提高查找的性能。堆排序算法就是先把那个无序的系统搞成一种叫做堆的有序形式,并且每次拿出一个最小(或最大)元素后,再次保持它的堆的性质。
堆排序
堆是一棵二叉树,并且每个节点都大于等于该节点的子节点(称为大根堆),或者每个节点都小于等于该节点的子节点(称为小根堆)。聪明的你一定想到了,对于大根堆来说,s[0]就是最大的元素,每次输出它就行了。
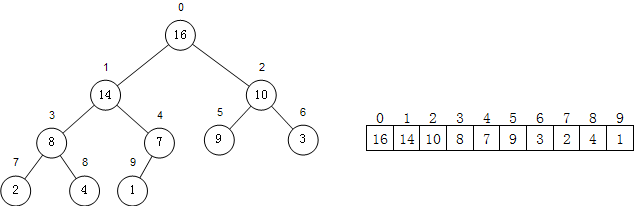
可以用数组来表现一颗二叉树。
通过对数组的下标的计算,就可以得到一个节点的父节点、左孩子、右孩子的下标。
view sourceprint?01 // 返回下标为nodeIndex的节点的父节点的下标
02 static int Parent(int nodeIndex)
03 {
04 return (nodeIndex-1) / 2;
05 }
06
07 // 返回下标为nodeIndex的节点的左孩子节点的下标
08 static int Left(int nodeIndex)
09 {
10 return (nodeIndex+1) * 2 - 1;
11 }
12
13 // 返回下标为nodeIndex的节点的右孩子节点的下标
14 static int Right(int nodeIndex)
15 {
16 return (nodeIndex + 1) * 2;
17 }
注:在《算法导论》里,数组的下界为1。但是在.Net里,数组的默认下界为0。虽然也可以创建下界为1的数组,但是效率会大打折扣,所以上面的计算树节点下标的方法还是基于下界为0的数组。建堆
第一步,自然是要把数组处理成堆。我们无法一下子做的这点,所以和插入排序一样,要使用增量的方法。先处理最后一个非叶子节点为根的子树——它最多只有3个节点——可以很容易让它符合堆的性质,然后依次处理倒数第2个非叶子节点为根的子树、倒数第3个非叶子节点为根的子树……麻烦的地方在于,这样下去总会遇到这样的情况:左孩子和右孩子可能不再是叶子节点,而是一棵树,所以我们的处理方法不能只考虑子节点是叶子节点的情况。虽然数据结构由数组变成了更为复杂的树,但是就像前面几篇曾经反复讨论过的,计算机之所以能够以有限的代码处理不确定数量的输入,一个常用的思路就是,将输入分解成具有相似结构和特性(或者说规律)的子集,增量地处理。Heapify()很好地诠释了什么叫“具有相似的结构和特性”——它每次面临的情况都是“左右孩子已经是堆,只有根节点可能小于它的左右孩子节点”。
view sourceprint?01 // 将数组s处理成大根堆
02 static void BuildHeap(int[] s)
03 {
04 // 从最后一个非叶子节点开始,直到根节点,调用Heapify()
05 for (int i = s.Length / 2 - 1; i >= 0; i--)
06 {
07 Heapify(s, i, s.Length - 1);
08 }
09 }
10
11 // 让s[nodeIndex]为根节点的整棵树保持大根堆的性质。
12 // 前置条件:以s[nodeIndex]的左孩子和右孩子为根节点的两颗树已经是大根堆
13 static void Heapify(int[] s, int nodeIndex, int heapEndIndex)
14 {
15 int leftIndex = Left(nodeIndex);
16 int rightIndex = Right(nodeIndex);
17
18 // 找出s[nodeIndex]、s[leftIndex]、s[rightIndex]三个元素中的最大的那个元素,并把它的下标赋值给largestIndex
19 int largestIndex = nodeIndex;
20 if (leftIndex <= heapEndIndex && s[leftIndex] > s[nodeIndex])
21 largestIndex = leftIndex;
22
补充:综合编程 , 其他综合 ,