当前位置:编程学习 > XML/UML >>
答案: 迭代的交错
基于我们对运筹学的一点经验,迭代设计之间肯定不是线性的关系。这样说的一个原因架构设计和后续的工作间还是时间差的。因此,我们不会傻到把时间浪费在等待其它工作上。一般而言,当下一次迭代的需求开始之后,详细需求开始之前,我们就已经可以开始下一次迭代的架构设计了。
各次迭代之间的时间距离要视项目的具体情况而定。比如,人员比较紧张的项目中,主要的架构设计人员可能也要担任编码人员的角色,下一次迭代的架构设计就可能要等到编码工作的高峰期过了之后。可是,多次的交错迭代就可能产生版本的问题。比如,本次的迭代的编码中发现了架构的一个问题,反馈给架构设计组,但是架构设计组已经根据伪修改的本次迭代的架构开始了下一次迭代的架构设计,这时候就会出现不同的设计之间的冲突问题。这种情况当然可以通过加强对设计模型的管理和引入版本控制机制来解决,但肯定会随之带来管理成本上升的问题,而这是不符合敏捷的思想的。这时候,团队设计就体现了他的威力了,这也是我们在团队设计中没有提到的一个原因。团队设计通过完全的沟通,可以解决架构设计中存在冲突的问题。
迭代频率
XP提倡迭代周期越短越好(XP建议为一到两周),这是个不错的提议。在这么短的一个迭代周期内,我们花在架构设计上的时间可能就只有一两个小时到半天的时间。这时候,会有一个很有意思的现象,你很难去区分架构设计和设计的概念了。因为在这么短的一个周期之内,完成的需求数量是很少的,可能就只有一两个用例或用户素材。因此,这几项需求的设计是不是属于架构设计呢?如果是的话,由于开发过程是由多次的迭代组成的,那么开发过程中的设计不都属于架构设计了吗?我们说,架构是一个相对的概念,是针对范围而言的,在传统的瀑布模型中,我们可以很容易的区分出架构设计和普通设计,如果我们把一次迭代看作是一个单独的生命周期,那么,普通的设计在这样一个范围之内也就是架构设计,他们并没有什么两样。但是,迭代周期中的架构设计是要遵循一定的原则的,这我们在下面还会提到。
我们希望迭代频率越快越好,但是这还要根据现实的情况而定。比如数据仓库项目,在项目的初期阶段,我们不得不花费大量的时间来进行数据建模的工作,这其实也是一项专门针对数据的架构设计,建立元数据,制定维,整理数据,这样子的过程很难分为多次的迭代周期来实现。
如何确定软件的迭代周期
可以说,如果一支开发团队没有相关迭代的概念,那么这支团队要立刻实现时隔两周迭代周期是非常困难的,,同时也是毫无意义的。就像我们在上面讨论的,影响迭代周期的因素很多,以至于我们那无法对迭代周期进行量化的定义。因此我们只能从定性的角度分析迭代周期的发展。
另一个了解迭代的方法是阅读XP的相关资料,我认为XP中关于迭代周期的使用是很不错的一种方法,只是他强调的如此短的迭代周期对于很多的软件团队而言都是难以实现的。
迭代周期的引入一定是一个从粗糙到精确的过程。迭代的本质其实是短周期的计划,因此这也是迭代周期越短对我们越有好处的一大原因,因为时间缩短了,计划的可预测性就增强了。我们知道,计划的制定是依赖于已往的经验,如果原先我们没有制定计划或细节计划的经验,那么我们的计划就一定是非常粗糙,最后的误差也一定很大。但是这没有关系,每一次的计划都会对下一次的计划产生正面的影响,等到经验足够的时候,计划将会非常的精确,最后的误差也会很小。
迭代周期的确定需要依赖于单位工作量。单位工作量指的是一定时间内你可以量化的最小的绩效。最简单的单位工作量是每位程序员一天的编码行数。可惜显示往往比较残酷,团队中不但有程序员的角色,还有设计师、测试人员、文档制作人员等角色的存在,单纯的编码行数是不能够作为唯一的统计依据的。同样,只强调编码行数,也会导致其它的问题,例如代码质量。为了保证统计的合理性,比较好的做法是一个团队实现某个功能所花费的天数作为单位工作量。这里讨论的内容实际是软件测量技术,如果有机会的话,再和大家探讨这个问题。
迭代周期和软件架构的改进
我们应用迭代方法的最大的目的就是为了稳步的改进软件架构。因此,我们需要了解架构是如何在软件开发的过程中不断演进的。在后面的文章中,我们会谈到用Refactoring的方法来改进软件架构,但是Refactoring的定义中强调,Refactoring必须在不修改代码的外部功能的情况下进行。对于架构来说,我们可以近乎等价的认为就是在外部接口不变的情况下对架构进行改进。而在实际的开发中,除非非常有经验,否则在软件开发全过程中保持所有的软件接口不变是一件非常困难的事情。因此,我们这里谈的架构的改进虽然和Refactoring有类似之处,但还是有区别的。
软件架构的改进在软件开发过程会经历一个振荡期,这个振荡期可能横跨了数个迭代周期,其间架构的设计将会经历剧烈的变化,但最后一定会取向于平稳。(如果项目后期没有出现设计平稳化的情况,那么很不幸,你的项目注定要失败了,要么是时间的问题,要么就是需求的问题)。关键的问题在于,我们有没有勇气,在架构需要改变的时候就毅然做出变化,而不是眼睁睁的看着问题变得越来越严重。最后的例子中,我们讨论三个迭代周期,假设我们在第二个周期的时候拒绝对架构进行改变,那么第三个周期一定是有如噩梦一般。变化,才有可能成功。
我们知道变化的重要性,但没有办法知道变化的确切时间。不过我们可以从开发过程中嗅到架构需要变化的气味:当程序中重复的代码逐渐变多的时候,当某些类变得格外的臃肿的时候,当编码人员的编码速度开始下降的时候,当需求出现大量的变动的时候。
实例
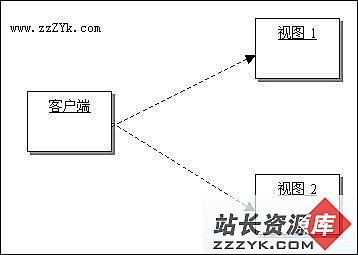
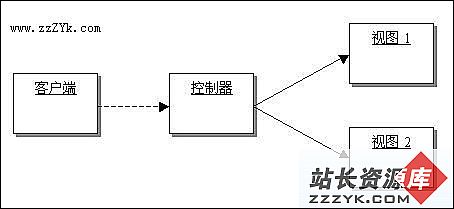
从这一周开始,我和我的小组将要负责对软件项目中的表示层的设计。在这个迭代周期中,我们的任务是要为客户端提供6到10个的视图。由于视图并不很多,表示层的架构设计非常的简单:
准确的说,这里谈不上设计,只是简单让客户端访问不同的视图而已。当然,在设计的示意图中,我们并没有必要画出所有的视图来,只要能够表达客户端和视图的关联性就可以了。
(架构设计需要和具体的实现绑定,但是在这个例子中,为了着重体现设计的演进,因此把不必要的信息都删掉。在实际的设计中,视图可能是JSP页面,也可能是一个窗口。)
第一个迭代周的任务很快的完成了,小组负责的表示层模块也很顺利的和其它小组完成了对接,一个简陋但能够运转的小系统顺利的发布。客户观看了这个系统的演示,对系统提出了修改和补充。
第二个迭代周中,模块要处理的视图增加到了30个,视图之间存在相同的部分,并且,负责数据层的小组对我们说,由于客户需求的改进,同一个视图中将会出现不同的数据源。由于我们的视图中直接使用了数据层小组提供给我们的数据源的函数,这意味着我们的设计需要进行较大的调整。
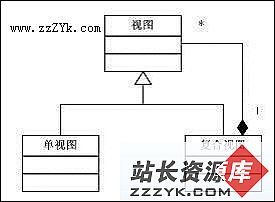
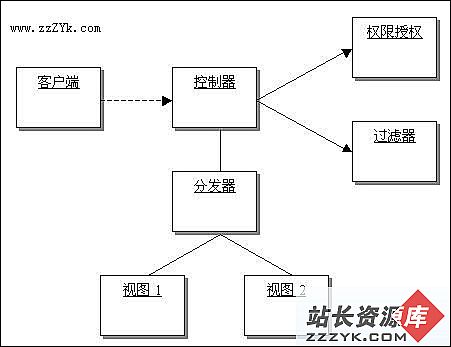
考虑到系统的视图的量大大的增加,我们有必要对视图进行集中的管理。前端控制器(Front Control)模式将会是一个不错的技巧。对于视图之间的普遍的重复部分,可以将视图划分为不同的子视图,再把子视图组合为各种各样的视图。这样我们就可以使用组合(Composite)模式:
客户的请求集中提交给控制器,控制器接受到客户的请求之后,根据一定的规则,来提供不同的视图来反馈给客户。控制器是一个具有扩展能力的设计,目前的视图数量并不多,因此仍然可以使用控制器来直接分配视图。如果视图的处理规则比较复杂,我们还可以使用创建工厂(Create Factory)模式来专门处理生成视图的问题。对于视图来说,使用组合模式,把多个不同数据源的视图组合为复杂的视图。例如,一个JSP的页面中,可能需要分为头页面和尾页面。
项目进入第三个迭代周期之后,表示层的需求进一步复杂化。我们需要处理权限信息、需要处理数据的合法性判断、还需要面对更多的视图带来的复杂程度上升的问题。
表示层的权限处理比较简单,我们可以从前端控制器中增加权限控制的模块。同时,为了解决合法性判断问题,我们又增加了一个数据过滤链模块,来完成数据的合法性判断和转换的工作。为了不使得控制器部分的功能过于复杂,我们把原先属于控制器的视图分发功能转移到新的分发器模块,而控制器专门负责用户请求、视图的控制。
我们来回顾这个例子,从迭代周期1中的需求最为简单,其实,现实中的项目刚开始的需求虽然未必会像例子中的那么简单,但一定不会过于复杂,因此迭代周期1的设计也非常的简单。到了迭代周期2的时候,需求开始变得复杂,按照原先的架构继续设计的话,必然会导致很多的问题,因此对架构进行改进是必要的。我们看到,新的设计能够满足新的需求。同样的,迭代周期3的需求更加的复杂,因此设计也随之演进。这就是我们在文章的开始提到的"Evolutionary Design"的演进的思想。
『引自 IBM DW中国』
上一个:XML入门 (下)
下一个:Martin Fowler关于MDA的见解