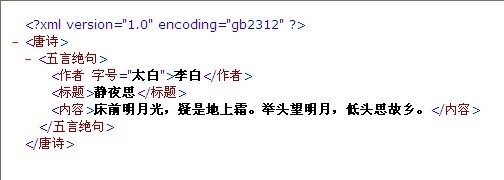
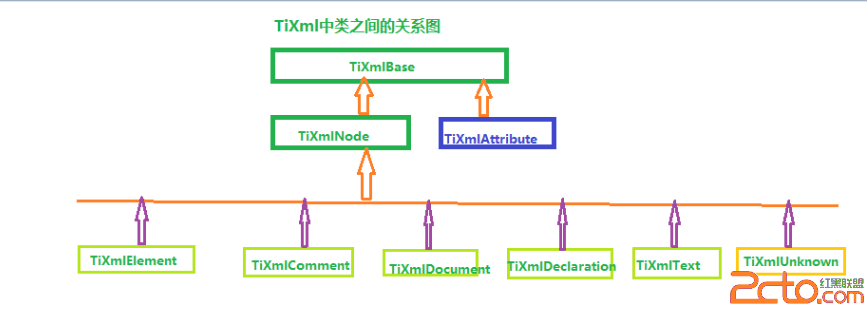
java解析xml文件
在java环境下读取xml文件的方法主要有4种:DOM、SAX、JDOM、JAXB
1. DOM(Document Object Model)
此 方法主要由W3C提供,它将xml文件全部读入内存中,然后将各个元素组成一棵数据树,以便快速的访问各个节点 。 因此非常消耗系统性能 ,对比较大的文档不适宜采用DOM方法来解析。 DOM API 直接沿袭了 XML 规范。每个结点都可以扩展的基于 Node 的接口,就多态性的观点来讲,它是优秀的,但是在 Java 语言中的应用不方便,并且可读性不强。
实例:
Java代码 import javax.xml.parsers.*;
//XML解析器接口
import org.w3c.dom.*;
//XML的DOM实现
import org.apache.crimson.tree.XmlDocument;
//写XML文件要用到
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//允许名字空间
factory.setNamespaceAware(true);
//允许验证
factory.setValidating(true);
//获得DocumentBuilder的一个实例
try {
DocumentBuilder builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException pce) {
System.err.println(pce);
// 出异常时输出异常信息,然后退出,下同
System.exit(1);
}
//解析文档,并获得一个Document实例。
try {
Document doc = builder.parse(fileURI);
} catch (DOMException dom) {
System.err.println(dom.getMessage());
System.exit(1);
} catch (IOException ioe) {
System.err.println(ioe);
System.exit(1);
}
//获得根节点StuInfo
Element elmtStuInfo = doc.getDocumentElement();
//得到所有student节点
NodeList nlStudent = elmtStuInfo.getElementsByTagNameNS(
strNamespace, "student");
for (……){
//当前student节点元素
Element elmtStudent = (Element)nlStudent.item(i);
NodeList nlCurrent = elmtStudent.getElementsByTagNameNS(
strNamespace, "name");
}
[java] import javax.xml.parsers.*;
//XML解析器接口
import org.w3c.dom.*;
//XML的DOM实现
import org.apache.crimson.tree.XmlDocument;
//写XML文件要用到
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//允许名字空间
factory.setNamespaceAware(true);
//允许验证
factory.setValidating(true);
//获得DocumentBuilder的一个实例
try {
DocumentBuilder builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException pce) {
System.err.println(pce);
// 出异常时输出异常信息,然后退出,下同
System.exit(1);
}
//解析文档,并获得一个Document实例。
try {
Document doc = builder.parse(fileURI);
} catch (DOMException dom) {
System.err.println(dom.getMessage());
System.exit(1);
} catch (IOException ioe) {
System.err.println(ioe);
System.exit(1);
}
//获得根节点StuInfo
Element elmtStuInfo = doc.getDocumentElement();
//得到所有student节点
NodeList nlStudent = elmtStuInfo.getElementsByTagNameNS(
strNamespace, "student");
for (……){
//当前student节点元素
Element elmtStudent = (Element)nlStudent.item(i);
NodeList nlCurrent = elmtStudent.getElementsByTagNameNS(
strNamespace, "name");
}
import javax.xml.parsers.*;
//XML解析器接口
import org.w3c.dom.*;
//XML的DOM实现
import org.apache.crimson.tree.XmlDocument;
//写XML文件要用到
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//允许名字空间
factory.setNamespaceAware(true);
//允许验证
factory.setValidating(true);
//获得DocumentBuilder的一个实例
try {
DocumentBuilder builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException pce) {
System.err.println(pce);
// 出异常时输出异常信息,然后退出,下同
System.exit(1);
}
//解析文档,并获得一个Document实例。
try {
Document doc = builder.parse(fileURI);
} catch (DOMException dom) {
System.err.println(dom.getMessage());
System.exit(1);
} catch (IOException ioe) {
System.err.println(ioe);
System.exit(1);
}
//获得根节点StuInfo
Element elmtStuInfo = doc.getDocumentElement();
//得到所有student节点
NodeList nlStudent = elmtStuInfo.getElementsByTagNameNS(
strNamespace, "student");
for (……){
//当前student节点元素
Element elmtStudent = (Element)nlStudent.item(i);
NodeList nlCurrent = elmtStudent.getElementsByTagNameNS(
strNamespace, "name");
}对于读取得方法其实是很简单的,写入xml文件也是一样不复杂。
Java代码 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = null;
try {
builder = factory .newDocumentBuilder();
} catch (ParserConfigurationException pce) {
System.err.println(pce);
System.exit(1);
}
Document doc = null;
doc = builder .newDocument();
//下面是建立XML文档内容的过程,
//先建立根元素"学生花名册"
Element root = doc.createElement("学生花名册");
//根元素添加上文档
补充:软件开发 , Java ,