[每日一题] OCP1z0-047 :2013-08-01正则表达式--- REGEXP_REPLACE函数
[每日一题] OCP1z0-047 :2013-08-01正则表达式--- REGEXP_REPLACE函数
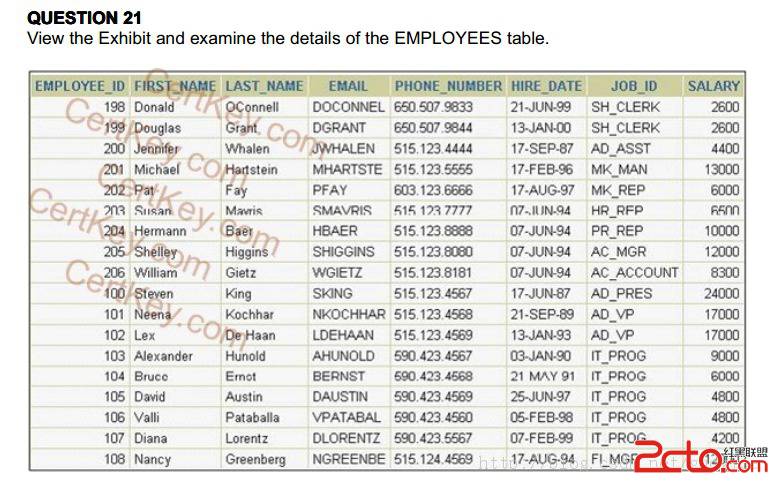

这题又是考正则表达式,我们先根据题意,操作如下:
[html]
hr@OCM> col "PHONE NUMBER" for a50
hr@OCM> SELECT phone_number,REGEXP_REPLACE(phone_number,'([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})','(\1) \2-\3') "PHONE NUMBER"
2 FROM employees;
PHONE_NUMBER PHONE NUMBER
-------------------- --------------------------------------------------
650.507.9833 (650) 507-9833
650.507.9844 (650) 507-9844
515.123.4444 (515) 123-4444
011.44.1644.429264 011.44.1644.429264
011.44.1644.429263 011.44.1644.429263
011.44.1644.429262 011.44.1644.429262
省略结果。。。。。
650.501.4876 (650) 501-4876
650.507.9811 (650) 507-9811
650.507.9822 (650) 507-9822
107 rows selected.
根据查询结果可以得出正确答案是:C
*************************************************************
REGEXP_REPLACE函数
让我们首先看一下传统的REPLACE SQL函数,它把一个字符串用另一个字符串来替换。假设您的数据在正文中有不必要的空格,您希望用单个空格来替换它们。利用REPLACE函数,您需要准确地列出您要替换多少个空格。然而,多余空格的数目在正文的各处可能不是相同的。下面的示例在Joe和Smith之间有三个空格。REPLACE函数的参数指定要用一个空格来替换两个空格。在这种情况下,结果在原来的字符串的Joe和Smith之间留下了一个额外的空格。
[html]
SELECT REPLACE('Joe Smith',' ', ' ')
AS replace
FROM dual
REPLACE
---------
Joe Smith
REGEXP_REPLACE函数把替换功能向前推进了一步,其语法在表 9中列出。以下查询用单个空格替换了任意两个或更多的空格。( )子表达式包含了单个空格,它可以按{2,}的指示重复两次或更多次。
[html]
SELECT REGEXP_REPLACE('Joe Smith',
'( ){2,}', ' ')
AS RX_REPLACE
FROM dual
RX_REPLACE
----------
Joe Smith
后向引用
正则表达式的一个有用的特性是能够存储子表达式供以后重用;这也被称为后向引用(在表 10 中对其进行了概述)。它允许复杂的替换功能,如在新的位置上交换模式或显示重复出现的单词或字母。子表达式的匹配部分保存在临时缓冲区中。缓冲区从左至右进行编号,并利用\digit 符号进行访问,其中digit 是 1 到 9 之间的一个数字,它匹配第 digit 个子表达式,子表达式用一组圆括号来显示。
接下来的例子显示了通过按编号引用各个子表达式将姓名 Ellen Hildi Smith 转变为 Smith, Ellen Hildi。
[html]
SELECT REGEXP_REPLACE(
'Ellen Hildi Smith',
'(.*) (.*) (.*)', '\3, \1 \2')
FROM dual
REGEXP_REPLACE('EL
------------------
Smith, Ellen Hildi
该 SQL 语句显示了用圆括号括住的三个单独的子表达式。每一个单独的子表达式包含一个匹配元字符 (.),并紧跟着 * 元字符,表示任何字符(除换行符之外)都必须匹配零次或更多次。空格将各个子表达式分开,空格也必须匹配。圆括号创建获取值的子表达式,并且可以用\digit 来引用。第一个子表达式被赋值为 \1 ,第二个 \2,以此类推。这些后向引用被用在这个函数的最后一个参数 (\3, \1 \2) 中,这个函数有效地返回了替换子字符串,并按期望的格式来排列它们(包括逗号和空格)。表 11 详细说明了该正则表达式的各个组成部分。
后向引用对替换、格式化和代替值非常有用,并且您可以用它们来查找相邻出现的值。接下来的例子显示了使用REGEP_SUBSTR 函数来查找任意被空格隔开的重复出现的字母数字值。显示的结果给出了识别重复出现的单词is 的子字符串。
[html] SELECT REGEXP_SUBSTR( 'The final test is is the implementation', ([[:alnum:]]+)([[:space:]]+)\1') AS substr FROM dual SUBSTR ------ is is
来自官方文档:

Purpose
REGEXP_REPLACE extends the functionality of the REPLACE function by letting you search a string for a regular expression pattern. By default, the function returnssource_char with every occurrence of the regular expression pattern replaced withreplace_string. The string returned is in the same character set as source_char. The function returns VARCHAR2 if the first argument is not a LOB and returnsCLOB if the first argument is a LOB.
This function complies with the POSIX regular expression standard and the Unicode Regular Expression Guidelines. For more information, please refer toAppendix C, "Oracle Regular Expression Support".
source_char is a character expression that serves as the search value. It is commonly a character column and can be of any of the datatypesCHAR, VARCHAR2, NCHAR, NVARCHAR2,CLOB or NCLOB.
pattern is the regular expression. It is usually a text literal and can be of any of the datatypesCHAR, VARCHAR2, NCHAR, or NVARCHAR2. It can contain up to 512 bytes. If the datatype ofpattern is different from the datatype of source_char, Oracle Database convertspattern to the datatype of source_char. For a listing of the operators you can specify inpattern, please refer to Appendix C, "Oracle Regular Expression Support".
replace_string can be of any of the datatypes CHAR, VARCHAR2, NCHAR, NVARCHAR2, CLOB, orNCLOB. If replace_string is a CLOB or NCLOB, then Oracle truncates replace_string to 32K. The replace_string can contain up to 500 backreferences to subexpressions in the form\n, where n is a number from 1 to 9. If n is the backslash character inreplace_string, then you must precede it with the escape character (\\). For more information on backreference expressions, please refer to the notes to"Oracle Regular Expression Support", Table C-1.
position is a positive integer indicating the character of source_char where Oracle should begin the search. The default is 1, meaning that Oracle begins the search at the first character ofsource_char.
occurrence is a nonnegative integer indicating the occurrence of the replace operation:
If you specify 0, then Oracle replaces all occurrences of the match.
If you specify a positive integer n, then Oracle replaces the nth occurrence.
match_parameter is a text literal that lets you change the default matching behavior of the function. This argument affects only the matching process and has no effect onreplace_string. You can specify one or more of the following values formatch_parameter:
'i' specifies case-insensitive matching.
'c' specifies case-sensitive matching.
'n' allows the period (.), which is the match-any-character character, to match the newline character. If you omit this parameter, the period does not match the newline character.
'm' treats the source string as multiple lines. Oracle interprets^ and $ as the start and end, respectively, of any line anywhere in the source string, rather than only at the start or end of the entire source string. If you omit this parameter, Oracle treats the source string as a single line.
'x' ignores whitespace characters. By default, whitespace characters match themselves.
If you specify multiple contradictory values, Oracle uses the last value. For example, if you specify'ic', then Oracle uses case-sensitive matching. If you specify a character other than those shown above, then Oracle returns an error.
If you omit match_parameter, then:
The default case sensitivity is determined by the value of th