mysql中order by 语句的用法 索引优化
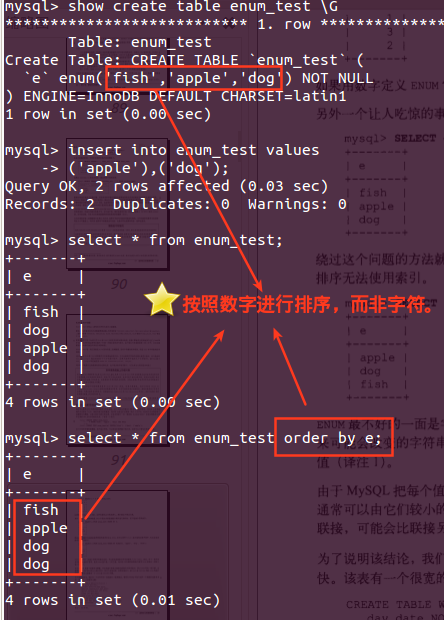
MySQL Order By keyword是用来给记录中的数据进行分类的。
MySQL Order By Keyword根据关键词分类
ORDER BY keyword是用来给记录中的数据进行分类的。
MySQL Order By语法
| 代码如下 | 复制代码 |
| SELECT column_name(s) FROM table_name ORDER BY column_name |
|
注意:SQL语句是“字母大小写不敏感”的语句(它不区分字母的大小写),即:“ORDER BY”和“order by”是一样的。
ORDER BY 关键词用于对记录集中的数据进行排序。
例子
下面的例子选取 "Persons" 表中的存储的所有数据,并根据 "Age" 列对结果进行排序:
| 代码如下 | 复制代码 |
|
<?php mysql_select_db("my_db", $con); $result = mysql_query("SELECT * FROM Persons ORDER BY age"); while($row = mysql_fetch_array($result)) mysql_close($con); |
|
以上代码的输出:
| 代码如下 | 复制代码 |
| Glenn Quagmire 33 Peter Griffin 35 |
|
升序或降序的排序
如果您使用 ORDER BY 关键词,记录集的排序顺序默认是升序(1 在 9 之前,"a" 在 "p" 之前)。
请使用 DESC 关键词来设定降序排序(9 在 1 之前,"p" 在 "a" 之前):
注:
如果我们在执行select语句的时候使用ORDER BY (DESC),那么它首先会对所有记录按照关键字有一个排序,然后依次读取所需的记录,而不是先选出记录再进行降序排列
MySQL ORDER BY 的实现分析
下面将通过实例分析两种排序实现方式及实现图解:
假设有 Table A 和 B 两个表结构分别如下:
sky@localhost : example 01:48:21> show create table AG
| 代码如下 | 复制代码 |
|
*************************** 1. row *************************** sky@localhost : example 01:48:32> show create table BG |
|
1、利用有序索引进行排序,实际上就是当我们 Query 的 ORDER BY 条件和 Query 的执行计划中所利用的 Index 的索引键(或前面几个索引键)完全一致,且索引访问方式为 rang、 ref 或者 index 的时候,MySQL 可以利用索引顺序而直接取得已经排好序的数据。这种方式的 ORDER BY 基本上可以说是最优的排序方式了,因为 MySQL 不需要进行实际的排序操作。
假设我们在Table A 和 B 上执行如下SQL:
| 代码如下 | 复制代码 |
| sky@localhost : example 01:44:28> EXPLAIN SELECT A.* FROM A,B -> WHERE A.c1 > 2 AND A.c2 < 5 AND A.c2 = B.c2 ORDER BY A.c1G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: A type: range possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 3 Extra: Using where *************************** 2. row *************************** id: 1 select_type: SIMPLE table: B type: ref possible_keys: B_c2_ind key: B_c2_ind key_len: 7 ref: example.A.c2 rows: 2 Extra: Using where; Using index |
|
我们通过执行计划可以看出,MySQL实际上并没有进行实际的排序操作,实际上其整个执行过程如下图所示:
2、通过相应的排序算法,将取得的数据在内存中进行排序方式,MySQL 比需要将数据在内存中进行排序,所使用的内存区域也就是我们通过 sort_buffer_size 系统变量所设置的排序区。这个排序区是每个 Thread 独享的,所以说可能在同一时刻在 MySQL 中可能存在多个 sort buffer 内存区域。
第二种方式在 MySQL Query Optimizer 所给出的执行计划(通过 EXPLAIN 命令查看)中被称为 filesort。在这种方式中,主要是由于没有可以利用的有序索引取得有序的数据,MySQL只能通过将取得的数据在内存中进行排序然后再将数据返回给客户端。在 MySQL 中 filesort 的实现算法实际上是有两种的,一种是首先根据相应的条件取出相应的排序字段和可以直接定位行数据的行指针信息,然后在 sort buffer 中进行排序。另外一种是一次性取出满足条件行的所有字段,然后在 sort buffer 中进行排序。
在 MySQL4.1 版本之前只有第一种排序算法,第二种算法是从 MySQL4.1开始的改进算法,主要目的是为了减少第一次算法中需要两次访问表数据的 IO 操作,将两次变成了一次,但相应也会耗用更多的 sort buffer 空间。当然,MySQL4.1开始的以后所有版本同时也支持第一种算法,MySQL 主要通过比较我们所设定的系统参数 max_length_for_sort_data 的大小和 Query 语句所取出的字段类型大小总和来判定需要使用哪一种排序算法。如果 max_length_for_sort_data 更大,则使用第二种优化后的算法,反之使用第一种算法。所以如果希望 ORDER BY 操作的效率尽可能的高,一定要主义 max_length_for_sort_data 参数的设置。曾经就有同事的数据库出现大量的排序等待,造成系统负载很高,而且响应时间变得很长,最后查出正是因为 MySQL 使用了传统的第一种排序算法而导致,在加大了 max_length_for_sort_data 参数值之后,系统负载马上得到了大的缓解,响应也快了很多。
我们再看看 MySQL 需要使用 filesort 实现排序的实例。
假设我们改变一下我们的 Query,换成通过A.c2来排序,再看看情况:
| 代码如下 | 复制代码 |
| sky@localhost : example 01:54:23> EXPLAIN SELECT A.* FROM A,B -> WHERE A.c1 > 2 AND A.c2 < 5 AND A.c2 = B.c2 ORDER BY A.c2G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: A type: range possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 3 Extra: Using where; Using filesort *************************** 2. row *************************** id: 1 select_type: SIMPLE table: B type: ref possible_keys: B_c2_ind key: B_c2_ind key_len: 7 ref: example.A.c2 rows: 2 Extra: Using where; Using index |
|
MySQL 从 Table A 中取出了符合条件的数据,由于取得的数据并不满足 ORDER BY 条件,所以 MySQL 进行了 filesort 操作,在 MySQL 中,filesort 操作还有一个比较奇怪的限制,那就是其数据源必须是来源于一个 Table,所以,如果我们的排序数据如果是两个(或者更多个) Table 通过 Join所得出的,那么 MySQL 必须通过先创建一个临时表(Temporary Table),然后再将此临时表的数据进行排序,如下例所示:
| 代码如下 | 复制代码 |
|
sky@localhost : example 02:46:15> explain select A.* from A,B |
|
这个执行计划的输出还是有点奇怪的,不知道为什么,MySQL Query Optimizer 将 “Using temporary” 过程显示在第一行对 Table A 的操作中,难道只是为让执行计划的输出少一行
MySQL Order By索引优化方法
尽管 ORDER BY 不是和索引的顺序准确匹配,索引还是可以被用到,只要不用的索引部分和所有的额外的 ORDER BY 字段在 WHERE 子句中都被包括了。
使用索引的MySQL Order By
下列的几个查询都会使用索引来解决 ORDER BY 或 GROUP BY 部分:
| 代码如下 | 复制代码 |
| SELECT * FROM t1 ORDER BY key_part1,key_part2,... ; SELECT * FROM t1 WHERE key_part1=constant ORDER BY key_part2; SELECT * FROM t1 WHERE key_part1=constant GROUP BY key_part2; SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 DESC; SELECT * FROM t1 WHERE key_part1=1 ORDER BY key_part1 DESC, key_part2 DESC; |
|
不使用索引的MySQL Order By
在另一些情况下,MySQL无法使用索引来满足 ORDER BY,尽管它会使用索引来找到记录来匹配 WHERE 子句。这些情况如下:
* 对不同的索引键做 ORDER BY :
| 代码如下 | 复制代码 |
| SELECT * FROM t1 ORDER BY key1, key2; | |
* 在非连续的索引键部分上做 ORDER BY:
| 代码如下 | 复制代码 |
| SELECT * FROM t1 WHERE key2=constant ORDER BY key_part2; | |
* 同时使用了 ASC 和 DESC:
| 代码如下 | 复制代码 |
| SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC; |
|
* 用于搜索记录的索引键和做 ORDER BY 的不是同一个:
| 代码如下 | 复制代码 |
| SELECT * FROM t1 WHERE key2=constant ORDER BY key1; | |
* 有很多表一起做连接,而且读取的记录中在 ORDER BY 中的字段都不全是来自第一个非常数的表中(也就是说,在 EXPLAIN 分析的结果中的第一个表的连接类型不是 const)。
* 使用了不同的 ORDER BY 和 GROUP BY 表达式。
* 表索引中的记录不是按序存储。例如,HASH 和 HEAP 表就是这样。
通过执行 EXPLAIN SELECT ... ORDER BY,就知道MySQL是否在查询中使用了索引。如果 Extra 字段的值是 Using filesort,则说明MySQL无法使用索引。详情请看"7.2.1 EXPLAIN Syntax (Get Information About a SELECT)"。当必须对结果进行排序时,MySQL 4.1以前 它使用了以下 filesort 算法:
复制代码 代码如下:
1. 根据索引键读取记录,或者扫描数据表。那些无法匹配 WHERE 分句的记录都会被略过。
2. 在缓冲中每条记录都用一个‘对'存储了2个值(索引键及记录指针)。缓冲的大小依据系统变量 sort_buffer_size 的值而定。
3. 当缓冲慢了时,就运行 qsort(快速排序)并将结果存储在临时文件中。将存储的块指针保存起来(如果所有的‘对'值都能保存在缓冲中,就无需创建临时文件了)。
4. 执行上面的操作,直到所有的记录都读取出来了。
5. 做一次多重合并,将多达 MERGEBUFF(7)个区域的块保存在另一个临时文件中。重复这个操作,直到所有在第一个文件的块都放到第二个文件了。
6. 重复以上操作,直到剩余的块数量小于 MERGEBUFF2 (15)。
7. 在最后一次多重合并时,只有记录的指针(排序索引键的最后部分)写到结果文件中去。
8. 通过读取结果文件中的记录指针来按序读取记录。想要优化这个操作,MySQL将记录指针读取放到一个大的块里,并且使用它来按序读取记录,将记录放到缓冲中。缓冲的大小由系统变量 read_rnd_buffer_size 的值而定。这个步骤的代码在源文件 `sql/records.cc' 中。
这个逼近算法的一个问题是,数据库读取了2次记录:一次是估算 WHERE 分句时,第二次是排序时。尽管第一次都成功读取记录了(例如,做了一次全表扫描),第二次是随机的读取(索引键已经排好序了,但是记录并没有)。在MySQL 4.1 及更新版本中,filesort 优化算法用于记录中不只包括索引键值和记录的位置,还包括查询中要求的字段。这么做避免了需要2次读取记录。改进的 filesort 算法做法大致如下:
1. 跟以前一样,读取匹配 WHERE 分句的记录。
2. 相对于每个记录,都记录了一个对应的;‘元组'信息信息,包括索引键值、记录位置、以及查询中所需要的所有字段。
3. 根据索引键对‘元组'信息进行排序。
4. 按序读取记录,不过是从已经排序过的‘元组'列表中读取记录,而非从数据表中再读取一次。
使用改进后的 filesort 算法相比原来的,‘元组'比‘对'需要占用更长的空间,它们很少正好适合放在排序缓冲中(缓冲的大小是由 sort_buffer_size 的值决定的)。因此,这就可能需要有更多的I/O操作,导致改进的算法更慢。为了避免使之变慢,这种优化方法只用于排序‘元组'中额外的字段的大小总和超过系统变量 max_length_for_sort_data 的情况(这个变量的值设置太高的一个表象就是高磁盘负载低CPU负载)。想要提高 ORDER BY 的速度,首先要看MySQL能否使用索引而非额外的排序过程。如果不能使用索引,可以试着遵循以下策略:
* 增加 sort_buffer_size 的值。
* 增加 read_rnd_buffer_size 的值。
* 修改 tmpdir,让它指向一个有很多剩余空间的专用文件系统。
好了,关于mysql 用法,索引用法,优化等待一系列的都有介绍了,大家可参考一下。
补充:数据库,mysql教程