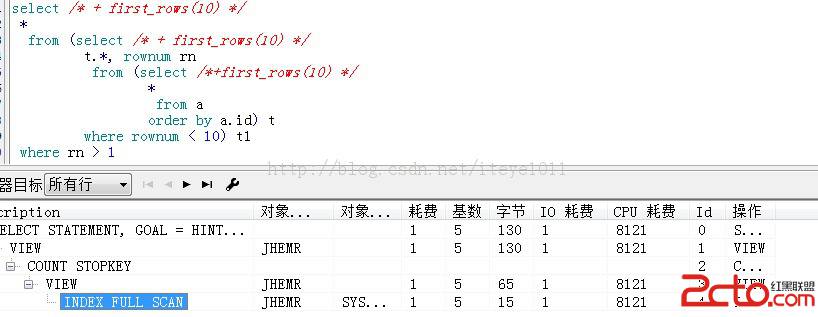
oracle 10g RAC节点重启,但是没有记录有效的日志信息--问题诊断
oracle 10g RAC 重启,但是没有记录有效的日志信息
from:
Oracle? Database Release Notes
10g Release 2 (10.2) for Linux x86-64
B15666-19
________________________________________
6.15 Configuring Oracle Clusterware Process Monitor Daemon
The 10.2.0.4 patch release for Oracle Clusterware on Linux includes
the Oracle Clusterware Process Monitor Daemon (oprocd). It is started
automatically by Oracle Clusterware to detect system hangs. When it
detects a system hang, it restarts the hung node.
Review the following configuration information if you have installed
the 10.2.0.4 patch set.
Oracle has found wide variations in sche易做图ng latencies observed
across operating systems and versions of operating systems. Because
of these sche易做图ng latencies, the default values for oprocd can be
overly sensitive, particularly under heavy system load, resulting in
unnecessary oprocd-initiated restarts (false restarts).
Oracle recommends that you address sche易做图ng latencies with your
operating system vendor to reduce or eliminate them as much as
possible, as they can cause other problems.
To overcome these sche易做图ng latencies, Oracle recommends that you
set the Oracle Clusterware parameter diagwait to the value 13. This
setting increases the time for failed nodes to flush final trace
files, which helps to debug the cause of a node failure. You must
shut down the cluster to change the diagwait setting. However, if you
prefer, you can use the default timing threshold for diagwait. In
that case, you do not need to perform the procedure documented here.
If you require more aggressive failover times to meet more stringent
service level requirements, then you should open a service request
with Oracle Support to receive advice about how to tune for lower
failover settings.
Note:
Changing the diagwait parameter requires a clusterwide shutdown. Oracle recommends that you change the diagwait setting either immediately after the initial installation, or during a scheduled outage.
Log in as root, and run the following command on all nodes, where
CRS_home is the home directory of the Oracle Clusterware
installation:
# CRS_home/bin/crsctl stop crs
Enter the following command, where CRS_home is the Oracle Clusterware
home:
# CRS_home/bin/oprocd stop
Repeat this command on all nodes.
From one node of the cluster, change the value of the diagwait
parameter to 13 seconds by issuing the following command as root:
# CRS_home/bin/crsctl set css diagwait 13 -force
Restart the Oracle Clusterware by running the following command on
all nodes:
# CRS_home/bin/crsctl start crs
Run the following command to ensure that Oracle Clusterware is
functioning properly:
# CRS_home/bin/crsctl check crs
来自IBM的解释:
Server running AIX with Oracle RAC reboots itself
Technote (troubleshooting)
Problem(Abstract)
Server running AIX with Oracle RAC reboots itself with no warning
Symptom
AIX server shuts down and/or reboots.
A REBOOT_ID is logged in /var/adm/ras/errlog indicating "SYSTEM
SHUTDOWN BY USER" although no shutdown or reboot command was issued
by any user.
example error message...
LABEL: REBOOT_ID
IDENTIFIER: 2BFA76F6
Date/Time: Wed Dec 3 08:19:09 2008
Sequence Number: 1447
Machine Id: 0000ABCD1234
Node Id: nodeA
Class: S
Type: TEMP
Resource Name: SYSPROC
Description
SYSTEM SHUTDOWN BY USER
Probable Causes
SYSTEM SHUTDOWN
Detail Data
USER ID
0
0=SOFT IPL 1=HALT 2=TIME REBOOT
0
TIME TO REBOOT (FOR TIMED REBOOT ONLY)
0
Cause
Oracle Real Application Clusters (RAC) is known to reboot the
operating system with no warning due to configuration of the oprocd
daemon
Environment
AIX with Oracle RAC
Diagnosing the problem
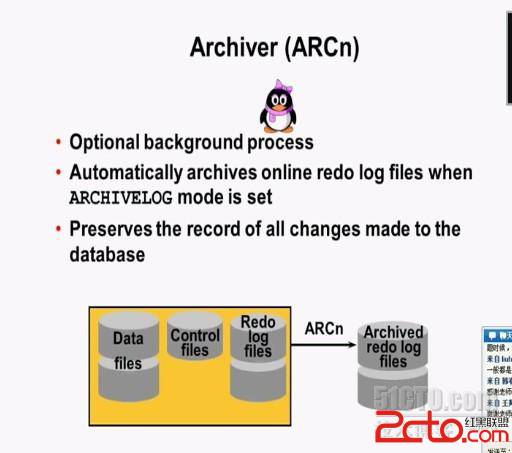
Oracle Real Application Clusters (RAC) typically runs a process called oprocd.
The idea of OPROCD is quite straightforward. It’s goal is to provide
I/O fencing. Basically oprocd works by setting a timer, then
sleeping. If, when it wakes up again and gets scheduled onto cpu, it
sees that a longer time has passed than the acceptable margin, oprocd
will decide to reboot the node.
You can check for the oprocd process with the ps command...
# ps -ef | grep oprocd
root 221672 1 0 08:27:44 - 0:00
/u01/crs/oracle/product/10.2.0/crs_1/bin/oprocd run -t 1000 -m 500 -f
These options to oprocd are saying -t 1000 (wake up every 1000 ms)
and -m 500 (allow up to 500 ms margin of error on the time that
oprocd wakes up before rebooting). In other words, if oprocd wakes up
after > 1.5 secs it’s going to force a reboot.
Resolving the problem
The timeout and margin times are computed from the elements of
diagwait and reboot time and it isn't recommended changing them via
the init.cssd file, but rather through the command 'crsctl set css
diagwait <secs>'.
There is a formula involved in the calculation of the times. For
example, if the reboot time is 3 and you submit a diagwait setting of
13 you will get -t 1000 -m 10000.
# crsctl set css diagwait 13 -force
# ps -ef | grep oprocd
root 221672 1 0 08:27:44 - 0:00
/u01/crs/oracle/product/10.2.0/crs_1/bin/oprocd run -t 1000 -m 10000
-f
You can see that the margin has changed to 10000 ms, that is 10
seconds in place of the default 0.5 seconds. This is a 20 fold
increase allows oprocd more time to determine if the node needs to be
rebooted.
IBM recommends the customer contact Oracle Support before modifying
this value.
IBM and Oracle came to the agreement that a diagwait value of 13 is a
suitable value if the best practices are used...
http://w3-03.ibm.com/support/techdocs/atsmastr.nsf/WebIndex/WP101513
IBM recommends customers follow best practices, and if possible
update to AIX 6.1 or AIX 7.1 with current Technology Levels which
include the new non-pagable kernel as the preferred corrective
action.
The Oracle master document can be found here... http://www.oracle.com/technetwork/database/clusterware/overview/rac-aix-system-stability-131022.pdf
ADDENDUM:
The following Oracle document provides additional information on the
cssdagent process which is related to oprocd...
http://docs.oracle.com/cd/E14072_01/rac.112/e10717/intro.htm
The cssdagent process monitors the cluster and provides I/O fencing.