NoSQL的数据建模技术
这是一篇很牛逼的技术文章,讲述如何对NoSQL 的数据进行建模。英文原文:http://highlyscalable.wordpress.com/2012/03/01/nosql-data-modeling-techniques/
NoSQL databases are often compared by various non-functional criteria, such as scalability, performance, and consistency. This aspect of NoSQL is well-studied both in practice and theory because specific non-functional properties are often the main justification for NoSQL usage and fundamental results on distributed systems like CAP theorem are well applicable to the NoSQL systems. At the same time, NoSQL data modeling is not so well studied and lacks of systematic theory like in relational databases. In this article I provide a short comparison of NoSQL system families from the data modeling point of view and digest several common modeling techniques.
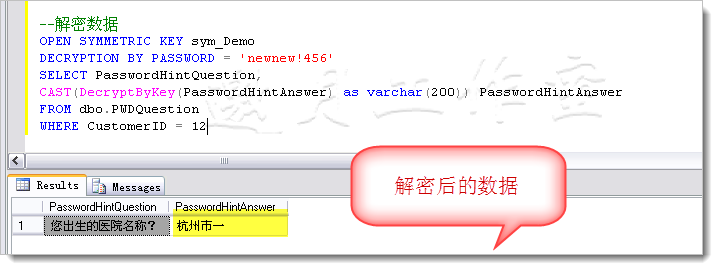
To explore data modeling techniques, we have to start with some more or less systematic view of NoSQL data models that preferably reveals trends and interconnections. The following figure depicts imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full Text Search Engines, and Graph databases:
NoSQL Data Models
First, we should note that SQL and relational model in general were designed long time ago to interact with the end user. This user-oriented nature had vast implications:
End user is often interested in aggregated reporting information, not in separate data items, and SQL pays a lot of attention to this aspect.
No one can expect human users to explicitly control concurrency, integrity, consistency, or data types validity. That’s why SQL pays a lot of attention to transactional guaranties, schemas, and referential integrity.
On the other hand, it turned out that software applications are not so often interested in in-database aggregation and able to control, at least in many cases, integrity and validity themselves. Besides this, elimination of these features had extremely important influence on performance and scalability of the stores. And this was where a new evolution of data models began:
Key-Value storage is a very simplistic, but very powerful model. Many techniques that are described below are perfectly applicable to this model.
One of the most significant shortcomings of the Key-Value model is a poor applicability to cases that require processing of key ranges. Ordered Key-Value model overcomes this limitation and significantly improves aggregation capabilities.
Ordered Key-Value model is very powerful, but it does not provide any framework for value modeling. In general, value modeling can be done by an application, but BigTable-style databases go further and model values as a map-of-maps-of-maps, namely, column families, columns, and timestamped versions.
Document databases advance the BigTable model offering two significant improvements. The first one is values with schemes of arbitrary complexity, not just a map-of-maps. The second one is database-managed indexes, at least in some implementations. Full Text Search Engines can be considered as allied species in the sense that they also offer flexible schema and automatic indexes. The main difference is that Document database group indexes by field names, as apposed to Search Engines that group indexes by field values. It is also worth noting that some Key-Value stores like Oracle Coherence gradually move towards Document databases via addition of indexes and in-database entry processors.
Finally, Graph data models can be considered as a side branch of evolution that origins from the Ordered Key-Value models. Graph databases allow to model business entities very transparently (this depends on that), but hierarchical modeling techniques make other data models very competitive in this area too. Graph databases are allied to Document databases because many implementations allow to model value as a map or document.
General Notes on NoSQL Data Modeling
The rest of this article describes concrete data modeling techniques and patterns. As a preface, I would like to provide a few general notes on NoSQL data modeling:
NoSQL data modeling often starts from the application-specific queries as opposed to relational modeling:
Relational modeling is typically driven by structure of available data, the main design theme is ”What answers do I have?”
NoSQL data modeling is typically driven by application-specific access patterns, i.e. types of queries to be supported. The main design theme is ”What questions do I have?”
NoSQL data modeling often requires deeper understanding of data structures and algorithms than relational database modeling does. In this article I describe several well-known data structures that are not specific for NoSQL, but are very useful in practical NoSQL modeling.
Data duplication and denormalization are the first-class citizens.
Relational databases are not very convenient for hierarchical or graph-like data modeling and processing. Graph databases are obviously a perfect solution for this area, but actually most of NoSQL solutions are surprisingly strong for such problems. That is why the current article devotes a separate section to hierarchical data modeling.
Although data modeling techniques are basically implementation agnostic, this is a list of the particular systems that I had in mind working on this article:
Key-Value Stores: Oracle Coherence, Redis, Kyoto Cabinet
BigTable-style Databases: Apache HBase, Apache Cassandra
Document Databases: MongoDB, CouchDB
Full Text Search Engines: Apache Lucene, Apache Solr
Graph Databases: neo4j, FlockDB
Conceptual Techniques
This section is devoted to the basic principles of NoSQL data modeling.
(1) Denormalization
Denormalization can be defined as copying of the same data into multiple documents or tables in order to simplify/optimize query processing or to fit user’s data into particular data model. Most techniques described in this article leverage denormalization in one or another form.
In general, denormalization is helpful for the following trade-offs:
Query data volume or IO per query VS total data volume. Using denormalization one can group all data that are needed to process a query in one place. This often means that for different query flows the same data will be accessed in different combinations. Hence we need to copy the same data and increase total data volume.
Processing complexity VS total data volume. Modeling-time normalization and consequent query-time joins obviously increase complexity of the query processor. Especially in distributed systems. Denormalization allows to store data in a query-friendly form to simplify query processing.
Applicability: Key-Value Stores, Document Databases, BigTable-style Databases
(2) Aggregates
All major genres of NoSQL provide soft schema capabilities in one way or another:
Key-Value Stores and Graph Databases typically do not pose constraints on values, so value can be of arbitrary format. It is also possible to vary a number of records for one business entity using composite keys. For example, user account can be modeled as a set of entries with composite keys like UserID_name, UserID_email, UserID_messages and so on. If user has no email or messages then a corresponding entry is not recorded.
BigTable model supports soft schema via variable set of columns within a column family and variable number of versions for one cell.
Document databases are inherently schema-less, although some of them allow to validate incomi