自己翻译的书(关于ASP.NET),希望对大家有帮助
不知道是否侵权,如果不侵权的话我会慢慢把所以翻译的都发上来的。希望对想学习ASP.NET的人有帮助。翻译的书是:A. Russell Jones的Mastering ASP.Net with C#. 从一楼起我会陆续贴上来的 --------------------编程问答-------------------- Mastering ASP.NET with C#
第一章: 屏幕之后 — 网络应用程序是怎样工作的
综述
在你能更好的理解一个C#应用可以做到之前,你需要在大概念上理解什么会发生当一个网络请求出现时。因为一个网络应用通常是一些简单的HTML页面以及更复杂的动态页面的组合,你需要理解服务器是怎么样满足那些不需要代码的网络请求。相当一大部分的后台会话以及数据的传输甚至是发生在用户的请求到达你的代码之前。
一个网络应用被很自然的分成至少两层——客户端和服务器端。这一章节的目的在于给予你一个有关客户端和服务器端通讯的清楚的理解。另外,你将会学到怎么样把C#融合到这种通讯中并且它能怎么帮你实现网络应用程序。
网络请求(Web Request)是怎样工作的
一个网络请求需要两个部分,网络服务器(Web Server)和客户端(Client)。客户端(在当前)通常是一个浏览器(Browser),但是它也可以是另外一种程序,例如,蜘蛛程序(Spider) (蜘蛛程序是一种在网络连接间爬行并收集信息的程序)或者是一个代理(agent) (代理是一种目的在于找到特定的信息——通常是通过搜索引擎——的程序),一个标准的执行程序,一个无线设备,或者是一个发自嵌入性程序芯片中的请求,比如冰箱。这本书主要面向但不仅仅局限于浏览器客户端。因此,你可以认为浏览器和客户端和其他的书中讲的是同样的概念。我会提前知会你什么时候这些概念是不可替换的。
服务器和客户端通常在不同的计算机上,但是这并不是必需的。你可以使用一个浏览器来向运行在同一台电脑上的服务器上请求页面——事实上,那可能是在你的开发机上运行大部分书中例子的设置方法。问题在于:无论服务器和客户端是否在同一台机器上或者是地球两端的不同机器上,请求应该是按照几乎相同的方式工作的。
服务器和客户端使用提前订好的协议(Protocol)来互相通讯。协议就是用一个两方都同意的方法来初始化一个会话(Session),来回传递信息,并且停止会话。一些协议用于网络通讯,最普通的就是用于网页请求的超文本传输协议(HTTP),用于加密网页请求的安全的超文本传输协议(HTTPS),用于二进制文件数据传输的文件传输协议(FTP),用于新闻组的网络新闻传输协议(NNTP)。然而无论协议是如何使用,网络请求都是依托在一个叫做传输控制协议/互联网协议(TCP/IP)的网络协议,该协议是一个可以决定两台电脑交换信息的基本传输标准。
服务器计算机耐心的等待,直到一个请求到达来初始化通讯。在一个网络应用程序中,客户端总是会发送初始化信息来启动一个会话——而服务器只能相应。你会发现如果只写独立程序会有一些挫败感。会话初始化过程包含一系列预定于的字节(Byte)串。字节内容不重要——唯一重要的事情是两台计算机认为这些字节串是初始化信息。当一个服务器收到初始化请求,它会返回另一个字节串给客户端来证明它知道了这个传输。两台计算机的交谈会以这种来回应答的方式继续下去。如果计算机会说话,你可以想象这个对话是这样进行的:
客户端:你好?
服务器:你好。我说英语
客户端:我也说英语
服务器:有什么可以为你做的?
客户端:我想要一个在/mySite/myFiles/file1.htm的文件
服务器:那个文件已经被移动到/mySite/oldFiles/file1.htm
客户端:不好意思。再见。
服务器:再见。
客户端:你好?
服务器:你好。我说英语
客户端:我也说英语
服务器:有什么可以为你做的?
客户端:我想要一个在/mySite/oldFiles/file1.htm的文件
服务器:这里是那个文件的一些信息。
客户端:谢谢。请发给我数据。
服务器:开始传输,发送包(Packet)1,发送包2,发送包3… …
客户端:我收到包1,包2有错误,我收到包3,我收到包4.
服务器:重新发送包2.
这次通许持续到传输结束。
服务器:所有的包已发送。
客户端:所有的包正常接收。再见。
服务器:再见
TCP/IP协议是众多计算机传输协议的一种,但是因为计算机的普及,它变得无所不在。你不需要知道太多关于怎么使用TCP/IP协议——底层协议几乎就是完全透明的。然后,你确实需要知道一点点关于一台机器怎样找到另一台机器并发起一个会话。
客户端请求的内容是什么
当你在浏览器地址栏里面输入一个请求或者是点击一个超链接,浏览器会打包请求并且发送URL一个重要的部分,也就是域名,到一个域名解析服务器,通常叫做DNS服务器。这个DNS服务器一般位于你的互联网服务提供商(ISP)处。域名解析服务器维护了一个数据库的域名,每一个域名都对应于一个IP地址。计算机不识字,所以域名解析服务器就把请求地址翻译成数字。你在连接中或者地址栏看到的文本格式的域名事实上是一个对于人类友好的IP地址。IP地址是一组介于0-255的四个数字,中间以冒号分隔:例如,204.285.113.34。每一个三元组是一个八位位组。
每一个IP地址唯一地确定一台计算机。如果在第一个域名解析服务器的数据库中没有找到请求的地址,它就会转发该请求到更高一层的域名解析服务器。最后,如果没有一个域名解析服务器能翻译该请求到一个IP地址,该请求就会到达其中某个最高层的域名解析服务器,该服务器维护了所有公共注册的IP地址。如果没有域名解析服务器能解析该地址,一个失败的解析应答会沿着域名解析服务器传到你的浏览器。届时,你会看到一个错误信息。
如果域名解析服务器发现IP地址请求的题目,她会缓存该请求,以便不再需要联系更高一层的域名解析服务器。缓存时间会在一定的时间内失效,叫做存活时间(TTL),所以如果下一个请求超过了TTL,域名解析服务器,就会依据下一次到来的请求,务必联系更高一层的服务器。域名解析服务器会返回IP地址到浏览器,浏览器会使用该IP地址来联系相应的网络服务器。许多网络页面包含到其他文件的引用,这些文件必须由服务器提供以保证页面的完整性。然后,浏览器只能一次请求一个文件。比如:网页中的图像请求需要对每一个图像的独立请求。因此,显示一个页面的过程通常包含一系列服务器和浏览器之间的通讯。更典型的情况是,浏览器先接收主页面,之后处理它来找到其他的文件引用,同时,在请求引用文件的同时开始显示主要页面。这就是为什么在一个页面加载的时候你经常看到“占位符”。主页面包含对其他包含图片的文件的引用,但是,主页面不能包含图片本身。
服务器是怎么响应的——准备
从服务器端来看,每一次通讯都是一次新的客户端和服务器端的接触。默认来说,服务器按照先来先服务(First-come, first-serve)的次序处理请求。服务器不会“记得”任何特定的浏览器。现代的浏览器以及服务器使用HTTP的1.1版本,该版本以保持通讯可用(Keep-alive Connection)的方式实现。正如你预料的那样,这意味着连接本身,一旦建立,就能够在一些列的请求时保持可用,而不需要服务器和客户端之间为每一个文件都重新查找IP和初始化。尽管HTTP以该方式实现,每个文件的发送仍然需要一个独立的请求和相应循环。
URL的构成
那行你键入浏览器地址栏,并用来请求文件的文字被叫做通用地址定位器(URL)。服务器按照一个标准程序来处理每一个请求。首先,它通过分解URL成不同的部分来分析请求。”/”,”:”,”.”,”?”以及”&”——都叫做分隔符——使得分隔非常简单。每个部分都有一个特定的功能。以下是一个简单的URL请求:
http://www.microsoft.com:80/CSharpASP/default.htm?Page=1&&Para=2
以下部分显示了那个URL请求每一部分的名称和功能。
HTTP 协议。告诉服务器该使用什么协议来相应请求。
www.microsoft.com 域名。这部分会翻译成IP地址。域名本身包含几个部分,这几个部分被”.”分隔成几个部分:主机名,www;企业域名,microsoft;已经顶级域名,com。一共只有几个顶级域名,包括org(组织),gov(政府),以及net(互联网)
80 端口。一个服务器有很多端口,每一个指定一个服务器的“监听”地点。一个端口号就是指定一个特定的地点(一共有65537个可能的端口)。随着时间的推移,端口的使用变得特殊。例如,在例子中我使用了80号端口,因为这是标准的(默认的)HTTP端口号。但是你可以让服务器使用任何端口监听请求。
CSharpASP 虚拟路径。服务器会把这个名字翻译成一个在硬盘上的物理路径。一个虚拟路径是一个速记名,一个指向物理路径的“指针”。虚拟路径和物理路径的名字不需要相同。一种定义虚拟路径的方式是通过服务器的管理接口(Administrative Interface)。另一种方式是通过在VS.NET创建一个新的网络应用或者是网络服务工程来创建虚拟路径。例如,当你创建一个新的网络应用程序或者网络服务工程,VS.NET会为你创建一个虚拟路径。
default.htm 文件名。服务器会返回文件的内容给客户端。如果文件被服务器认为是一个可执行文件(例如ASP文件)而不是一个HTML文件,服务器会执行这个包含在文件中的程序并且返回结果给客户端显示而不是返回文件本身的内容。如果文件没有被认出来,服务器会提供文件的下载给客户端。
?(问号)分隔符。问号可以用来从URL请求中分隔请求和附加参数(Parameter)。我们的URL例子包含两个参数:
Page=1 and Para=2.
Page 参数名。那些你写的程序,例如ASP页面,能够读取参数并且利用它们来传递信息。
=(等号)分隔符。等号用于把参数名和参数值分开。
1 参数值。参数Page的值为1。注意:浏览器会以一个字符串的方式发送所有的参数。字符串(String)是一系列的字符:一个单词(Word)是一个字符串,一个句子(Sentence)是一个字符串,一个随机数字和字母序列是一个字符串——任何形式的文字都是一个字符串。你的程序可以自由的解析只包含数字形式字符的字符串为数字,但是为了安全起见,你应该强制转换这些字符串为数字模式。
& (与)分隔符。”&”分隔参数-值对。
Para=2 第二个参数名和参数值。
服务器翻译URL路径
你不必使用“真的”或者物理路径来处理物理请求。你可以使用虚拟路径来请求页面。当解析URL完成,服务器会把虚拟路径翻译成物理路径。例如,URL中的虚拟路径http://myServer/myPath/myFile.asp 是myPath。myPath虚拟路径会映射到本地路径,例如:C:\inetpub\wwwroot\CSharpASP\myFile.asp或者是映射到一个网络通用名称会话(UNC)名,例如:\\someServer\somePath\CSharpASP\myFile.asp.
服务器检查资源
服务器会定位请求的文件。如果文件不存在,服务器会返回一个错误信息——通常是HTTP 404——文件没有找到。你可能在浏览网站的时候已经看到这个错误信息;如果没有,你比我幸运多了。
服务器检查权限
在定位到资源之后,服务器会检查请求的账户是否有足够的权限来访问资源。默认来说,网络信息服务器(IIS)请求会使用一个叫做IUSR_Machinename的帐号,这个Machinename是服务器计算机的名称。你经常会听到“匿名”账户,因为服务器没有办法得知发起请求用户的任何真正的账户信息。对于ASP.NET页面,IIS会使用SYSTEM账户或者另一个叫做“aspnet_wp_account (ASPNET)”的Guest账户
例如,如果用户用户请求一个它没有阅读权限的文件,服务器会返回一个错误信息,通常是HTTP 403——访问被拒绝。实际的错误文字依赖于生成的特定的错误。例如,403错误信息有几种子错误。你能够在IIS默认的网站属性对话框找到完整的错误列表。服务器提供了默认的错误信息,但是它也允许你去定制错误信息。默认来说,IIS会从你的系统根目录 %SystemRoot%\ help\common\ directory读取错误信息,这里,变量%SystemRoot%代表你的NT路径名,通常是叫做winnt。
服务器是怎么响应的——实现
图像文件,Word文档,HTML文件,ASP文件,可执行文件,CGI脚本——服务器是怎么知道怎么处理这些不同的请求文件的呢?事实上,服务器会用不同的方式区分这些文件类型。
IIS像Windows的资源管理器那样使用不同的文件后缀来区分不同的文件类型,例如,.asp,.htm,.exe,等等。当你在资源管理器中双击一个文件或者图标,它会在注册表中查找文件扩展名,注册表是一个特殊的数据库,它保存了系统和应用程序信息。注册表为每一种注册的文件扩展名保存了一个条目。每一个扩展名有一个相应的文件类型条目。每一个文件类型条目有一个相应的可执行文件或者文件处理程序。服务器在文件名中提取扩展名,查找相关的程序,并且启动那个程序来返回相应的文件。IIS遵循了相同的步骤来决定怎样响应请求。
其他的服务器也使用文件扩展名来决定怎么处理一个文件请求,但是他们不使用注册表相关的方法。相应的,他们使用的独立的文件扩展名-程序关联(File Extension-to-Program Association)列表。列表中的条目叫做MIME类型,意味着多目的互联网邮件扩展(Multipurpose Internet Mail Extension),因为电子邮件程序需要知道邮件中的内容的不同类型。每一个MIME类型——就像注册表关联——对应于一个特定的程序或者动作。服务器会搜索目录列表来找到匹配请求文件扩展名的条目。大部分服务器会通过提供下载文件的方式来处理那些找不到匹配的扩展名的文件。一些服务器对于那些不包含文件名的URL提供了一个默认的动作。在这个例子中,大部分服务器会返回一些默认的文件列表——通常是叫做default.htm或者是index.htm的文件。你也可以为你的服务器配置默认的文件名,或者是对于在那个服务器上的所有的虚拟路径,也可以是那个服务器上每一个特定的虚拟路径。
当服务器生成响应时,它会开始把这些响应变成数据流,或者它会缓冲所有的响应,并且当响应完成时一次性的发送他们。响应分为两个部分:响应头(Response Header)和响应体(Response Body)。响应头包含了响应类型的信息。响应头也可以包含以下的部分:
响应代码
相应的MIME类型
响应的过期日期和时间
重定向URL
服务器想要存在客户端的任何Cookie值
Cookie是浏览器保存在内存中或者在客户端计算机的硬盘中的文本字符串。Cookie可以存活在整个Session的活动期间或者它也可以存活到一个特定的过期时间。浏览器会发送一个包含网站以及接下来的请求的Cookie给服务器。
注意: 媒体大肆宣传过Cookie。一些人非常了解这个让人担心的技术,所以他们在浏览器里面设置“不允许Cookie”。这意味着浏览器不会接受Cookie,这会对你的网站有显著的影响因为你必须有其他的方式来关联一个独立的浏览器会话和存储在你应用的服务器层面的值。这种不使用Cookie的方式是有办法解决的,但是这些方法非常不方便,并且他们也不会存在于浏览器会话之间。
客户端如何处理响应
客户端,通常是浏览器,需要理解服务器响应的内容是什么形式。客户端会读取MIME类型头来决定内容的类型。对于大部分请求,MIME类型头或者是text/html或者是图像类型,例如image/gif,但是它也可以是一个文字处理文件,一个视频,或者是一个音频文件,一个动画,或者其他类型的文件。浏览器使用注册表值或者MIME类型列表来决定怎么显示文件。对于标准HTML以及图像文件,浏览器使用一个内置的显示引擎。对于其他的文件类型,浏览器会寻求其他应用或插件的帮助,例如,RealPlayer,微软的Office来显示信息。浏览器会把它所有的或者部分的窗口区域以“帆布”(Canvas)的形式来让应用或者插件来“画”他们的内容。
当响应体包含HTML,浏览器会把结构化标记(Markup)和内容从文件中分离开。然后它使用结构化标记来决定内容怎么布局。现代HTML文件可以包含几种不同类型的内容以及结构化标记,文字,以及图像;浏览器会用不同的方法来处理他们。这些最普通的文件类型包括:
层叠样式表(Cascading Style Sheets) 这些特定格式的文本文件包含了怎样格式HTML文件内容的指令。浏览器使用层叠样式表来给页面中不同的元素内容赋予不同的字体,边框,可视化,定位,以及其他格式化信息。层叠样式表类型能够包含在一个标签(Tag)中,它能够被放在HTML页面的任何一个独立的区域,或者是存在于一个完整的独立文件中。所有的这些需要在浏览器处理完主页面请求,但是还没有现在是屏幕上之前。
脚本(Script) 所有的浏览器都能执行JavaScript程序,虽然他们可能用不同的方式执行它。名称“JavaScript”特定的对应于在网景(Netscape)的JavaScript脚本语言,但是有两个接近的变种——微软的Jscript脚本语言和ECMAScript——他们有完全相同的语法并且支持一个几乎相同的命令集。
注意:Jscript脚本语言不同于JScript.NET——其实,JScript.NET是一个更稳定的微软开发出加在VS.NET中的JScript版本
除了JScript, IE还支持VBScript,这是VB在应用上的一个子集,相应的,它也是微软的VB.NET前身的一个子集。
ActiveX部件或Java Applets 这些小程序在客户端而不是服务器端执行。ActiveX部件只能在IE或者Windows平台上运行(在本书书写时,其市场占用率有60%之多),然后Java Applets可以在几乎所有的浏览器和平台上运行。
注意:你可以在http://www.ecma.ch/stand/ecma-262.htm找到完整的ECMA-262规范。
XML 可扩张性标识语言很类似于HTML——两周都包含标签和内容。这并不让人吃惊,因为两周都是从标准型通用标识语言(SGML)衍生而来。HTML的标签描述了怎样显示内容,以及在一个有限的范围内可以显示内容的功能。XML的标签描述了内容是什么。换句话说,HTML主要是一个标准化和现实语言,然而XML是一个内容描述语言。两种语言互为补充。XML被首先应用在IE4上为“通道(Channel)”技术服务,该服务是一种相对不成功的技术,它可以让人们从各种不同的网站上订阅信息。IE4拥有一个通道栏来帮助人们管理他们的通道订阅。随着IE5的出现,微软抛弃了通道技术,但是扩展了浏览器对于XML的理解和灵活度以使得你在今天能在HTML文件中提供数据“岛(Island)”。你也可以提交一个XML以及XSL/XSLT(XSL/XSLT是一种目的类似于层叠样式表但是比其更强大的用XML写成的规则语言)的组合来在客户端生成HTML代码。XML/XSL组合让你从服务器端卸下处理的重负,因此可以提升你网站的可量测性(Scalability)。网景6提供了一个不同的——以显示为目的的——更现代的支持XML的类型。网景的解析引擎可以合并XML以及CSS层叠样式表来直接定义XML的显示格式。然后,网景没有直接的支持XSLT的转换,所以在没有中间转换的情况下,显示会有一定的现实。
--------------------编程问答-------------------- 动态网页介绍
我刚才介绍的客户端-服务器端-客户端的处理过程是非常重要的,因为它发生在在每次客户端联系服务器端来获取数据的过程中。这完全不同于你已经熟悉的单机模型或者是客户端-服务器端模型。因为客户端和服务器端不知道对方,所以对于每次交互,你必须发送,初始化或者存储适当的值来维持应用的可持续性。
让我们来看一个简单的例子。假设你有一个带有登录表单(Form)的安全站点。在一个标准的程序中,在用户成功登录之后,那就是唯一的你需要做的验证了。事实就是用户成功的登录意味着他已经被授权了使用应用程序的周期。相反的,当你登录了一个只有登陆框和密码框的网站时,服务器必须对你接下来的每一个请求进行重新验证。这可能就是一个很简单的工作,但是它必须对应用中的每个请求都加以实施。
事实上,那就是动态页面应用变得流行的原因。在一个允许匿名连接的网站上(就像大部分的网站那样),你能够授权给用户权限只有当你能够比较存储在服务器上用户名/密码的“真正的”备份。但是大部分情况下,HTML是一个适当的布局型语言,而不是编程语言。它需要其他代码的帮助才能授权用户。
另一个动态网页变得流行的原因就是信息属性的改变。静态页面对于文章,论文,图书和图像的支持非常好——总的来说,就是对于很少变化的信息支持很好。但是静态页面对于雇员和联系人列表,日历信息,新闻递送,体育比赛比分——总的来说,就是那些你需要每时每刻交互的数据的支持——不太好。数据改变太多以至于无法成功的在静态页面中被维护。另外,你不会想要总是以同样的方式看到相同的数据。我觉得我在这里有点废话——如果你不知道动态页面有这些优势,你根本不会买这本书。但是,如果可以注意到即使是动态页面也是会有一个可以预测的变化几率的,这是很有用的——我会在备注中讨论它。
服务器如何从内容中分离代码
在经典的ASP页面中,你可以通过放置一个特别的标签(<%%>)在代码前后或者是通过撰写脚本块来混合代码和内容。脚本是被包含在<script> 和</script>标签之中。经典的ASP使用.asp作为文件扩展名。当服务器接到一个来自ASP文件的请求,它会通过文件的扩展名认出这是一个ASP文件,所以这个请求需要ASP的处理器来回应这个请求。因此,服务器会传递这个请求给ASP引擎,这个引擎可以解析文件来把代码从标记中分离出来。ASP引擎开始处理代码,并且把结果和页面中的HTML混合,之后发送混合好的结果到客户端。ASP.NET使用一个类似的处理流程,但是文件的扩展名是.aspx而不是.asp。你仍然可以以完全相同的方法混合代码和内容,只是在ASP.NET中,你可以(并且应该)把代码放到一个分离的文件中,叫做后台代码类(code-behind class),因为这样做会提供一种更加干净的显示代码和应用代码的区分并且使得两者可以更加容易的被重用。在ASP.NET中,你可以把代码写在三个地方的任何一个——后台代码类,代码标签和脚本块。但是,ASP.NET引擎仍然需要为HTML文件解析代码标签。
服务器何时并且怎么样处理代码
ASP.NET引擎本身是一个互联网应用程序接口(ISAPI)应用。ISAPI应用程序是一些DLL,这些DLL会被加载进服务器的地址空间,所以他们非常快。不同的ISAPI应用程序会处理不同类型的请求。你可以为特别的文件扩展创建ISAPI应用,例如.asp或者.aspx,或者是为标准的文件类型,例如HTML和XML,进行特别的操作。
有两种ISAPI应用:扩展(Extension)和过滤器(Filter)。ASP.NET引擎本身就是一个ISAPI扩展。一个ISAPI扩展应用替代或者增强了标准的IIS响应。扩展应用在服务器收到一个关联与ISAPI扩展应用的DLL请求时被加载。相反的,ISAPI过滤器先被IIS加载并且通知服务器哪些过滤器事务(Event)可以 被处理。一旦某种类型的过滤器事务发生,IIS发出一个事务通知给相应的过滤器。
注意:你不能使用C#创建ISAPI应用程序——或者说是用托管代码(Managed Code)——尽管你能在VS.NET中使用非托管的C++代码或者是活动模板类(ATL)来创建它们。然而你可以使用C#重写(Override)默认的HttpApplication来提供更过种ISAPI应用。
ASP.NET页面如果包含代码标签或者是包含后台代码类,它就会越过标准的IIS响应程序。如果你的aspx页面不包含任何代码,ASP.NET引擎在完成页面解析之后就会认出这点。对于不包含任何代码的页面,ASP.NET引擎会在这个环节上缩短它的响应,并且继续标准的服务器处理程序。在IIS 5(ASP 版本3.0)中,标准的ASP页面就已经开始缩短无代码页面的响应时间。因此,不包含任何代码的ASP以及ASPX页面只比标准的HTML页面慢一点点。
客户端怎么与动态页面交互
那客户端是怎么与动态页面交互的呢?简单的回答是这样的:和其他任何种类的请求的处理模式一模一样。请记住,客户端和服务器几乎不了解对方。事实上,除了知道服务器的地址,客户端通常是完全摒弃服务器端的信息,然后服务器需要知道足够的客户端信息以保证可以提供适当的响应。
新的网络程序员通常会为客户端怎样响应动态及静态页面请求而感到疑惑。记住的要点是:对于客户端,请求的是动态页面或是静态页面是没有区别的。例如,对于客户端,请求一个aspx页面或者是HTML页面是没有区别的。记住,客户端基于MIME类型头的值来解析响应——但是并没有为动态生成的页面准备的特殊的MIME类型。MIME类型头对与动态或者静态页面是完全相同的。
HTML什么时候不够用
在这一章,我曾经提到几种不同的MIME类型的响应。这些类型非常重要,因为对于HTML本山来说,它并不是特别强大。幸运的是,现在变成网络程序员恰是好时候。浏览器已经过了幼年期(版本2和3),蹒跚期(版本4),并且在让其变成应用应用程序承载平台的路上有了很大的进步。尽管它们还是没有像Windows表单(Form)那么强大,但是在过去的五年中,它们取得了很大的进步,并且已经可以以一种很强大的方式操作HTML以及XML信息。
这些改变发生就是因为HTML是一种布局型语言。HTML不是一种样式语言,因此,层叠样式表才变得流行。HTML也不是一个图像描述或者是操作语言,因次,文档对象模型(DOM)才能帮你操作屏幕上对象的现实方式和位置。HTML也不是一个好的翻译和描述通用数据的语言,因此,XML才能变成现在浏览器工具集的一个组成部分。最后,对于这本书而言,最重要的是,HTML也不是一个编程语言。你必须使用某种编程语言来实施可用性检查以及逻辑操作。现代浏览器在某种程度上都是支持脚本语言的。
在IE 5x,或者网景6x,这些技术已经变得同气连枝。你既可以通过操作CSS或者XSL/XSLT来操作XML。你也可以使用DOM来改变层叠样式表并且动态改变目标的显示属性。你既可以直接用CSS(像是改变鼠标的形状)响应某些用户时间,也可以通过脚本来响应或者忽略所有的用户事务。
C#能做什么
既然你已经要让你自己使用服务器端最新的科技来创建动态页面应用,你应该知道C#可以做什么。让人意外的是,当你把网络编程变成这样几个组成部分的时候,网络编程和标准的应用程序编程之间的差距就很小了。
做If/Then的判断
If/Then是编程的关键。C#能够基于已知的标准做出判断。例如,判断一个用户是否以管理员,监督员或者是工人登录。C#能够选择适当的权限标准和响应。
使用判断代码,C#能够用于在文件中实现部分代码,包含或者不包含整个文件,或者是为一个特定的人在特定的时间创建全新的内容。
处理来自客户端的信息
一旦你创建了一个应用程序,你就需要处理来自客户端的信息。例如,当用户填好了表格,你需要验证这些信息,也许会把他们存储起来以备将来之需,并且反馈给用户。使用C#,你拥有访问用户发送所有信息的权限,并且你拥有对于服务器响应的完全控制。你可以使用你已知的编程经验来处理验证信息,保存数据到硬盘,并且格式一个响应。除了给予你一个可以做这是事情的编程语言,C#还提供了对于网络应用程序的更多支持。
C#网络应用程序使用ASP.NET框架来帮助你验证用户输入。例如,你可以在屏幕上放置一个控制,该控制可以保证请求域包含一个值,并且自动检查这个值是否合法。C#网络应用程序提供了可以简化磁盘和数据库操作的对象并且让你可以轻松地操作XML,XSLT以及值组。使用C#,你可以写出像是客户端脚本的服务器端代码。换句话说,你能够写出存在于服务器端的代码,但是这些代码可以以集权的方式响应客户端事件而不是写出没那么强大,但是却很难调试的客户端脚本。ASP.NET能够通过会话对象帮助你为每一个用户维护数据,通过缓存减少你服务器的工作量,并且通过自动恢复横跨几个服务器的输入控制值来维护一个一致的虚拟状态。
访问数据和文件
在大部分应用中,你也许会需要读取和存储永久数据。相比以前的ASP版本,ASP.NET使用.NET框架提供了一个非常强大的文件访问机制。例如,许多商业应用会在晚上从一个主框架或者是数据库服务器接收数据。很典型的,程序员会写一个特别的预定程序来读取或者解析以及包装新的数据文件进入一个适合于当前应用的表单。经常的,业务中断发生在一些意外发生使得数据文件处理过晚或者从来没有出现过。
很相似的,你难道没有曾经写过这样一些程序么?这个程序会创建一个文件,之后你会试着访问它只是为了找到用户已经删除或者在中途移动过文件。我知道——你一定写过这样的防卫代码使得你的程序能够恢复或者至少可以优雅的退出,对吗?
如果程序本身可以和文件系统交互,每当一个特定的目录发生改变应用程序都能收到通知,那许多应用程序的书写和维护能够变得更加容易。例如,如果你能够写出一段代码,这段代码可以在数据从主框架到达之时立刻开始数据导入处理,那么你就可以避免写一段检查文件的改变的时间循环程序或者是一个即使没有数据还在不停运转的排程应用程序。
相似的,如果在用户删除一个核心文件的时候你可以收到一个通知,那么,你不但可以避免写一个防卫程序,并且可以在第一时间阻止问题的发生。
你会发现使用C#会比使用以前的任何编程语言都要 更加容易的实现这些任务。你会发现如果使用C#,那最常用的文件和数据库操作变得更加简单(尽管解释起来有些麻烦)。例如,其中一个最普通的操作就是在一个HTML表格中显示数据库的查询结果。如果在经典的ASP应用中使用VBScript或者是Jscript代码,你必须在查询返回的结果集中不停的循环并且把这些值放入你自己设计的表格中。而在C#中,你可以获取到数据集(dataset)并且使用循环器(Repeater)来完成乏味的循环操作。
使用XML,CSS,XSLT,以及HTML来格式化响应信息
正如我前面所说的,你已经完成了从你应用返回的响应的完全的控制。直到现在,网络应用程序开发者需要担心的不仅仅是浏览器以及应用程序客户端的版本问题,并且网络客户端类型的大爆炸也是一件极其复杂的问题。手持设备,精密的互联网存取硬件设备,寻呼机,网络电话以及不断增长的标准应用程序已经超出了人类可以企及的格式化需求。
过去,对于大部分有简单的HTML以及脚本需求的网页,你可以为其准备两到三个版本——一个是对于完全白痴的没有任何动态HTML以及脚本能力的浏览者,另一个是对于网景4,还有一个是对于IE 4已经更高版本。但是随着客户端的类型和数目的增多,为每一种新的客户端类型创建新的HTML页面已经变得越来越不可能了。幸运的是,层叠样式表CSS和XML向正确的方向迈进了一大步。
使用层叠样式表,你能够调整一个页面使得页面可以满足不同的分辨率,颜色深度,以及可用性。但是层叠样式表只会影响到内容的显示属性——但是只使用层叠样式表,你不能为不同的设备调整内容本身。然后,通过XML,CSS以及XSLT的组合,你可以让两样都做到最好。XML可以保存数据,XSLT通过客户端类型过滤数据,层叠样式表CSS会控制被过滤的数据是如何在客户端的屏幕上显示。
VS可以帮助你创建所有这些文件类型,并且C#可以让你有计划的操作他们。而结果就是满足客户端特定显示需求的HTML。
启动并且和.NET以及COM+对象通讯
在过去的一两年中,ASP最具扩展性的模型就是使用ASP页面比HTML页面更多一些,这些ASP页面能够启动以微软事务服务器(MTS)或者COM+应用为宿主的COM模块。微软叫这个是Windows DNA。如果你曾经使用这个模型建立过应用,你会发现几乎没有什么改变,除了安装,移动,重命名以及版本模块变得更加容易。当然,这并不是一个小改变。
在.NET出现之前,你必须使用C++或者Delphi来创建适合于网络应用程序的自由线程(Free-threaded)的COM对象。(更具体的来说,一些人的确用VB写过多线程,但是看起来并不好看,而这也不是一个程序员都会有的技能)如果你没有写过独立(Stand-alone)程序,多线程看起来并不是什么大问题。毕竟,大部分的独立程序以及客户-服务器端应用程序并不需要多线程。然而,在网络环境中,这确实是一个大问题。网络应用程序几乎总是面对多个同步用户,到目前为止,.NET作为一个像Java一样适合于网络应用的语言,它必须具有多线程的能力。许多经典的ASP的程序员都是从VB程序员移植而来,所以他们倾向于使用哪种语言来生成部件。不幸的是,用VB 5/6生成的DLL都是房间线程的(Apartment Threaded)。不需要讲得太详细,这意味着网络应用程序不能存储使用VB 5/6写的对象而不引起严重的性能问题。
C#生成的对象本身就是自由线程的,所以你的网络应用程序能够安全的存储用C#写成的对象。当然,你仍然必须应对因同步的使用你的对象所引起的多线程问题,但是你可以标记特定的的代码段为危险的(Critical),因此可以序列化(Serializing)的访问这些代码段。当然,这是一个不同的故事了。
C#也可以让你访问传统的COM DLL,所以你可以直接使用已经存在的二进制代码而不必再用.NET语言重写一遍。有一些争论关于到底需要多久你才能做这个。个人认为,你可以在几年内优雅的升级COM DLL为.NET版本。为了在.NET中使用已经存在的COM DLL,你需要“导入(Import)”类型库。一种是通过使用TlbImp.exe。该方法会创建一个你能够使用它调用方法以及类属性的“包(Wrapper)”。当然,使用包会有一个轻量级的代价,但是当另一种方法是重写并测试已知代码的时候,这个代价一般都是可以接受的。
你也可以使用一种相反的方法,那就是用非托管的C++,VB5/6,Delphi或者任何的COM可控诉(COM-complaint)语言导出(Export).NET的汇编程序集(Assembly)。为了做这个,你必须使用TlbExp.exe。这个工具可以创建一个类型库但是不会注册它。尽管TlbExp很容易被记住(它是Tlblmp的相反的工具),另一个叫做RegAsm.exe的工具既能够注册,也可以同时创建类型库。在RegAsm.exe后使用/tlb会告诉该工具穿件一个类型库文件。你也可以使用RegAsm.exe产检一个REG(注册)文件而不是真的在你的汇编程序集里注册,这种方式在当你创建一个要安装到其他机器上的应用的安装程序时非常有用。
--------------------编程问答-------------------- C#在网络应用程序中的优点
C#是一个针对Windows平台的非常强大的创建应用程序的工具(也许在不久的将来,也会是面对其他的系统的)。但是它不仅仅只是一个用于创建应用程序的工具。如果你想要钻研到API层面或者是写足够的代码,只有很少功能C#能做而其他老的语言不能做。但是,说到提供对与某种应用的内置的支持,对于内存管理,杜宇面向对象开发,C#会极大的减少创建他们的工作量。
网络服务
网络服务其实就是一个运行在服务器上面向对象的网络接口。等等,你说,那不就是和分布式COM(DCOM)相同么?不准确,但是确实相似。DCOM让你的应用程序可以启动并且像在本地机上一样使用远程应用程序以及DLL。它通过在在事务的两端创建代理“存根”(Stub)来实现这些。DCOM包装了函数,子程序,方法,或者是你本地应用程序的属性,以及任何匿名参数,然后把他们通过网络发送到服务器的一个接收存根上。服务器存根会把值解包,启动对象或者应用程序(如果必要的话),并且做出决定,传递参数。返回值会以相反的操作进行。DCOM使用一个足够高效的二进制压缩包来通过网络发送数据。
当远程调用来自于一个硬连线的专有网络的主机中,DCOM的确是开创了一个时代。随着公司为了商业目的开始使用公共的互联网络时,网络不再是专有的了,相反,DCOM调用必须跨越公共网络和私有公司网络的界限。然而,让二进制数据跨越边界实在是有些危险,因为你不知道这些数据会做什么。例如,数据里面可能包含病毒程序。因此,公司都会布置防火墙以此来阻止二进制数据跨越边界。文本数据,像是HTML,可以畅通无阻的穿越边界,但是二进制数据不可以。不幸的是,通过防火墙来阻止DCOM进行简单的操作会有副作用,因为防火墙是没有办法区分有潜在危险的危险的公共二进制数据以及完全安全的DCOM二进制数据。
网络服务解决了这个问题。网络服务实现了和DCOM完全相同的功能——他们让你可以使用远程对象。然而,他们使用一个完全不同的机制,该机制被叫做简单对象访问协议(SOAP),来打包调用和参数数据。SOAP是文本文件模式。它使用XML来简化支持远程调用的各种值类型的语法。因为SOAP是文本文件,所以它能够穿越防火墙。然而,SOAP不是远程调用的必要条件;它仅仅是个标准的方便的实现方法。换句话说,你可以自由的书写你的哦远程包——但是如果你这样做,你必须也要同时创建你自己的翻译函数。
C#以及VS有对SOAP的支持。事实上,在C#中使用SOAP是完全透明的;.NET框架会承担所有值翻译和传递的任务,而让你可以集中精神创建应用程序本身。创建网络服务的过程和创建COM DLL的过程极度相似——或者就此而言,任何其他的.NET代码,因为你要把一个方法或者整个类当作网络服务就是去添加属性(Attribute)——元数据就是少量包含代码信息的元数据。
网络服务和SOAP的最大问题就是性能;它就是不能像使用DCOM和CORBA翻译二进制文件那样高效的翻译文本表达。然而,在这个危险的世界,SOAP是无可避免的灾难。而且我认为你会很惊奇网络服务到底可以运行多快。真正的性能区别当然是可以测量的,但是感知的性能区别是可以忽略的除非你在一个循环中进行了多次远程调用(而且你应该尽量在远程技术中避免这种情况)。
瘦客户端(Thin-Client)应用程序(网络表格)
C#和ASP.NET一致可以让你创建基于网络表格(Web Form)的应用程序。网络表格,我们将会在第四章介绍,“ASP.NET介绍”,第五章介绍,“网络表格介绍”,是一个集成了C#(或者任何将要出现的.NET语言)代码的HTML表格。如果你很熟悉ASP,JSP,或者是PHP,你会很快适应C#网络应用以及网络表格。如果你没有用以上任何技术写过网络应用程序,你应该感到很幸运的是现在加入到网络应用领域而不是以前,因为C#使得创建网络应用程序类似于创建Windows应用程序。
你可以通过拖拽控制器(Control)到网格设计界面来创建网络表格。当放置一个控制器之后,你可以双击它来添加代码一次来响应控制器事件。网络表格支持大部分相类似于Windows控制器的同系物(Analog),例如文本框,标签,控制面板以及列表框。他们甚至支持像计时器的不可见控制器。
撇开网络表格的方便性不谈,你仍然可以创建基于浏览器或者瘦客户端的应用程序,所以你可以期望失掉部分你能在Windows客户端实现的功能。然而(而且我认为这是你在.NET中可以看到的最大的改变),你不必局限在瘦客户端网络应用程序。通过把Windows客户端和网络服务组合起来,你非常容易的可以创建胖客户端(Rich-Client)应用程序。事实上,这门技术使得创建两种类型的应用程序都非常容易——并且让他们两者都以普通的集中式代码实现。
胖客户端(Rich-Client)应用程序(网络表格)
也许你会觉得很奇怪我在这本书中谈到网络应用程序的时候包含网络表格,但是我保证在你读完这本书之后,你不会觉得奇怪。胖客户端和瘦客户端的区别其实在飞快的减少。随着浏览器增加了更多的属性,他们在逐渐变“胖”。而且随着Windows表格应用获得网络应用能力,他们变得更有能力来支持更有分量的基于网络的服务。结果就是在网络表格还是Windows表格之间做决定是依赖于你是否能够很轻松的传递Windows表格应用代码到客户端,或者是你是否必须依赖于安装在客户端机器上的不管什么浏览器或者是“用户代理”的功能。
在本书中,你将要学习创建这两种类型的应用。你将会看到应用设计以及分布的不同,然后你就可以自行决定。
总结
你已经看到了在事务爆炸时客户端和网络服务器的通讯。客户端请求一般都是匿名的,所以如果你的应用程序要处理敏感数据,那你必须考虑安全和验证代码。在请求中间,服务器会“忘记”客户端,所以除非你强制客户端对每一次请求传递Cookie或者一些其他的标识记号(Identifying Token),服务器会假设客户端是全新的。网络应用程序使用这些标识记号来关联数据值和独立的浏览器或者是独立用户(在安全网站中)。你选择的在请求中维护这些数据值的策略叫做“状态维护”(State Maintenance),而且这是在创建网络应用程序时最难的问题。
C#通过网络表单,网络服务,健壮的网络状况,以及和ASP.NET的紧密集成帮助简化了网络应用程序的建立,以此提供了基础结构来支持网络请求。
尽管存在VS的网络表单编辑器,我们还是很有必要学习创建网络表单所使用的语言——HTML。幸运的是,作为一个致力于记住复杂代码操作的程序员,你会发现HTML非常简单且直白。你能够在半个小时学会基本的HTML。在第二章,“HTML基础”,我会给你展示半小时的HTML之旅,这些基本的HTML知识足够你理解在以下章节中出现的HTML代码。如果你已经熟悉HTML,你可以把这章当作一个回顾或者是直接跳过它并且直接开始阅读第三章,“动态网络应用指南”。
--------------------编程问答-------------------- 出书吧 --------------------编程问答-------------------- 神人!!!
但是,这样子对大家(包括你我他)都有用么?
极大地浪费了你的时间,而读者却基本不会看,所以,还是好意建议楼主放弃! --------------------编程问答-------------------- 第二章: HTML基础
综述
这一章包含了一个半小时的HTML之旅可以教你超文本标记性语言(HTML)的结构和编辑。如果你已经熟悉HTML,那么你可以直接跳过本章,并且直接阅读第三章,“动态网络应用指南”。如果你还不了解HTML,那你就应该读一下这章并且使用包含的文件作文一个起点来练习创建HTML。你应该觉得在开始创建C#应用程序之间学习HTML是对的。就像其他的想法一样,HTML就是一个你可以应用,组合并且扩展来创建非常复杂的结构的想法。
什么是HTML
HTML是一种标识语言,尽管它最初的目的是设计一种内容描述语言。像是一个文字处理器,它包含了一些命令,这些命令可以在很宽泛的范围内告诉计算机文档的内容是什么。例如,使用HTML,你可以告诉计算机当前的文档包含一个段落,一个项目符号利润表,一个表格或者是一个图片。HTML转发引擎符合显示文字和图像到屏幕上。HTML和文字处理器的不同在于文字处理器工作在一个私有的格式上。因为它们是私有的,所以一个文字处理器通常不能直接阅读另一个文字处理器的文件格式。相反的,文字处理器会使用一个特殊的程序,叫做导入(Import)/导出(Export)来把一种文件类型翻译成另一种。
相比较而言,HTML是一个开放的,世界范围的标准。如果你使用在版本3.2中的命令创建一个文件,它可以在世界的任何地方的任何操作系统的几乎所有的浏览器上显示。HTML最新的版本4.0现在已经在90%的浏览器上使用。
HTML是一个叫做标准通用标识语言(SGML)的一个子集。SGML已经被开发了大约15年并且包含许多HTML缺少的特性,但是也造成它实现起来非常复杂。这种复杂性使得它既难被创建也难被恰当的显示。
作为SGML语言的一个子集,HTML被用来在一个很慢的拨号网络链接(Dial-up Connection)——互联网——中提供轻量级的文字和图像显示标准。最开始,HTML只有很少的特性——在过去的几年中,它增长的非常缓慢。然而,你可以在几个小时之内学到HTML的核心命令集。
HTML只包含两种信息:标识(Markup),它包括在尖括号(<>)中所有的文字,以及内容(Content),它是所有的不包含在尖括号中的文字。这两点的不同是浏览器不会显示标识,相反的,标识包含了告诉浏览器怎样显示内容的信息。
例如,以下的HTML:
<html>
<head><title></title></head>
<body>
</body>
</html>
是一个完全正确的HTML文件。你可以保存这组命令为一个文件,并在你的浏览器中看一下,它会显示一个没有错误的文件——但是你不会看到其他的任何东西,因为这个文件不包含任何内容。所有的文字都是标识。
相反的,下面的文件不包含标识:
This is a file with no markup
尽管大部分浏览器会显示这个没有任何标识的文件的内容,但这并不是一个合法的HTML文件。
在尖括号之间的独立部分的标识叫做标签(Tag),有时也叫做命令(Command)。这里有两种类型的标签——开始标签和结束标签,而且他们通常是成对出现(尽管他们可能分散在文件的两个部分)。唯一的不同就是结束标签以斜杠”/”(Forward Slash)开始,例如</html>。除了斜杠,开始标签和结束标签是完全相同的。
HTML可以做什么
HTML可以让你创建半结构化(Semi-structured)的文档。头部的命令可以划分并且分类你的文档。HTML也有基本的命令来格式化和显示文本,图片,接收用户输入,并且发送用户信息到服务器去接受后端处理。另外,它也可以让你创建一个特殊的文本或者是图片域,当这个域被点击的时候,会跳到或者是从一个HTML文件超链接到另一个文件。因此,这就可以创建一系列相互关联的页面。
这一系列通过超链接创建的网页叫做一个程序;然而,这个程序并不像你要在这个书中要学到的程序因为这一系列的页面没有只能也不能做出任何判断。所有的功能都存在于HTML的作者所选择的标签集里面(那些主要工作是创建HTML文档的人们被叫做作者(Author),而不是程序员(Programmer))。在一个或者一组路径中把一系列的文件链接在一起叫做一个站点(site),或者是一个网站(Web site)。
尽管缺少决策制定能力,一个网站有两个主要的目的:
它为非程序员提供了一种创造功能完全的包含有用信息的吸引人的网站的方式。(当然,它也为人们提供了一种创造充满无用信息的毫无吸引力的网站的方式,但是我并不想谈论它。)
通过互联网,使得网站信息可以全球推广。
为什么HTML那么重要
在HTML出现之前,在屏幕上显示一个任何人使用任何操作系统都可以读的充满文本和图片信息的页面并不是那么容易。事实上,还没有任何简单的可以不用你自己写程序或者使用类似于PowerPoint的陈述程序就显示任何东西的方法。这种限制意味着只有那些在相同程序上使用相同程序——通常是使用相同版本的程序的——用户才能看到。
HTML之所以重要是因为它给千百万人提供了一种他们以前从没有看到过的访问在线信息的方式。HTML是第一种让非程序员可以在屏幕上用以显示文本和图片的方法,该方法不会只把读者局限于与内容的作者拥有相同的程序(或者是阅览器)的人群。在某种意义上说,浏览器是一个通用的内容阅览器,而且HTML是一个通用的文件格式。事实上,直到今天,HTML和文本曾经是唯一的两种通用文本模式;然而,现在我们可以加上XML了,XML可以解决许多文本和HTML没有办法解决的信息表达问题。
HTML的局限性
尽管HTML有广泛的应用并显示了强大的能力,事实上是它的通用文件模式,作为一种布局语言,以及文件模式,HTML还是在创建结构化文档的问题上有极大的限制。首先,平面HTML没有办法制定内容在页面中的特定位置,例如,是否水平,是否垂直,是否要沿着Z轴(z-axis)布局,这个Z轴可以用来控制对象出现的“层“。第二,正如我说的,HTML不是一个编程语言,所以它没有判断能力。第三,HTML是一种固定的标识语言。换句话说,所有的标签都是提前定义好的,你不能制定你自己的标签。万维网,或者说是W3C,定义了组成HTML的标签。 除非W3C扩展了标准,否则标签集是不会变的。这既有优点又有缺点。优点是大部分浏览器都能显示大部分的HTML。缺点是因为标签集被限定下来了, 这也鼓励——不对,是促使——许多公司会创建新的扩展标签集来增加更多的功能。
在如今,许多在HTML中有用的概念,例如表单,表格,脚本,框架,以及层叠样式表,都是以私有扩展的方式出现,但是之后被W3C采用并被加入到其标准之中(请参考www.w3.org来获取更多信息)。这些扩展最终变得很普遍,并且促使W3C重新评价并且更新HTML的标准。经过这种扩展以及修正过程,许多曾经是私有的扩展变成HTML标签集的一部分。因为这个,HTML已经有好几个版本。最近的就是HTML 4.01。
语法:标签和属性
一个合法的HTML文件只有少数几个要求。请看一下这个例子:
<html>
<head>
<title>Hello World</title>
</head>
<body>Hello World
</body>
</html>
这个例子既包含标签,也包含内容。标签就是在尖括号(<>)中的文本。如果你在浏览器中看一下这个文件,你会看到一个类似于图2.1显示的图像。

图2.1:Hello World文件(HelloWorld.htm)
HelloWorld.htm文件是一个很短但是完整的HTML文件。所有的HTML文件都以<html>标签为始,并以</html>为终(读成“html终结”或者“html结束”)。在这两个标签之间是其他标签以及内容。所以<html>标签包含其他标签。包含其他标签的标签被叫做包含标签(Containing Tags),或者更确切的说是块元素(Block Element)。在本书中,我将使用块元素来命名包含其他标签的标签。注意,<head></head>标签也是一个块元素,除此以外,它还包含一个<title></title>标签。
HTML标签分为两个部分——起始标签(Start Tag)以及结束标签(End Tag)。尽管并非所有的浏览器都要求在所有的情况下都要加上结束标签,你还是应该立刻养成这样做的习惯。因为当你使用XML的时候(也许你以后某个时候会使用XML),所有的类都需要结束标签。现在,我将不会对于每个标签都写上起始标签和结束标签。例如,当我要写一个标签</head><head>时,我会仅仅写成<head>。你可以假设结束标签还是存在的。
注意:HTML文件是文本文件。他们只包含两种类型的条目:指令(也叫做标签或者是标识)以及内容。你可以使用任何文本编辑器来编辑HTML文件。我比较喜欢使用网景浏览器来编辑小文件,用一个知道HTML的文本编辑器,例如VS HTML编辑器,HomeSite,Frontpage,或者是Dreamweaver来编辑大文件。因为这些编辑器会把标签染色,自动插入结束标签,通过IntelliSense或者是标签/属性列表来预测语法,并且可以提供许多能帮助编辑的特性。
什么是标签
根据你可以擅长的领域,你可以对标签有如下不同的理解方式。例如,一种方式是把标签想成一个嵌入式命令(Embedded Command)。标签制定了一部分文本,这部分文本会被浏览器做特殊的处理。处理方式会从“让下一个字符变成粗体”到“把下一行当作代码”等不同。另一种方式是把标签想成是隐藏信息的包装器。浏览器不会显示标签里面的信息。事实上,如果浏览器不理解那个标签类型,那它就会忽略它。如果你想要放一些信息在文件中,但是又不想让它在屏幕上显示出来,那你会发现这个非常方便。第三种方式是把标签想成一个对象。例如,<p>标签包含了一段话。一段话会有很多属性——缩排,词或字符计数器,样式——我保证当你使用一个单词处理器时,你一定会运行一个能够把段落当成对象的扫描程序。
什么是结束标签
结束标签只是很简单的标记文档的结束。计算机并不聪明——一旦你决定开始用粗体,那它会一直开到你关为止。就是一个警告:大部分浏览器会让你跳过许多通用的结束标签,但是一定要接受我的建议:不要忽略它们。在未来,你可能需要转换这些文档为XML格式——在XML中,结束标签是必不可少的。
为什么HTML看起来像<这样>
在HTML使用的尖括号是有一个很长的历史的。HTML从SGML中继承了语法,但是那并不是尖括号的唯一用途。在19世纪80年代末,我第一次在XyWrite中看到它们。XyWrite是一个文字处理器,该处理器使用HTML样的嵌入式指令并且它在作者之间非常流行。它流行的原因是它使用位和字节来表达信息,但是这是一个有趣的故事,所以请慢慢听我讲。
你在计算机里面输入的每一个字符其实都是一个特定的数字。对于不同的计算机系统,有几种不同的数字集。但是在今天,最常用的就是美国标准信息交组(ASCII)。例如,A的ASCII编码值就是65,空格的编码值是32,0的编码值是48。计算机并不会按照你做的来表达数字——它使用二进制记数法。由于历史原因,大部分现代的微型计算机只会操作8的倍数。每一个8位组叫做一个字节——一个字节可以有256种不同的值,对于表达字母,数字以及标点,一些控制字符,一些重读字符,以及少数可以用来画简单图像的线条是足够的。
所有可见字符都有一个低于128的值。大部分的文件类型,包括那时候的文字处理器,使用大写字母作为嵌入式指令。例如,一种文件类型可能会使用157作为一个段落开始的标记,158作为一个段落结束的标记。这个的原因是如果指令能够限定到一到两个字符,那么文件本身会小很多——当然,这些字符是需要在大部分文本文件中不常出现的。你必须记得,在那时,内存非常贵并且是限量供应的。相反的,XyWrite的指令最少可以用3个字节长来表达,而且很多人认为这是对空间的一种浪费。
让我们回到故事中来。记者是第一批通过电话系统来使用电子计算机通讯去发送文件。早期版本的通讯程序可以只使用7个位来表达信息——最后一位是停止位(Stop Bit)。因为如果你通过电流传输文件,那文件的格式化信息会丢失,所以他们不会使用那个需要大写字符集的程序。但是因为XyWrite使用尖括号,那就可以使用普通字符在7位内表达指令,所以就可以为XyWrite文件传输文本和格式化信息。所以XyWrite就通过把尖括号变成文字处理器的第一个字符来做标记。
好了,故事讲够了。其实HTML使用尖括号的真实原因是比较无趣的——这个模式已经在SGML被定义了。这种模式非常利于人们的读写,并且这种模式也非常容易让程序来解析——也就是说把他们分成几个部分。
属性语法
标签可以包含一个主要的指令以及无限的相关值,叫做属性(Attribute)。每个属性都有一个名字和对应的值。你必须把属性从指令或者是前面的属性中通过空白字符分离出来。空白字符包含空格符,制表符,以及回车符/换行符。浏览器会忽略空白字符(除非不存在)。对于浏览器而言,泛空格符就是另一种指令,叫做分隔符。分隔符通过字符或者是字符串来区分项目(Item)。使用泛空白符是非常自然的因为我们就是用它来分隔单词。
不同类型的分隔符有不同的含义。例如,除了在单词间使用空白符,我们也会在句子间使用句号。在HTML,尖括号区分标签,空白符区分属性,等号会把属性的名称从值中分离出来。类似的,HTML使用引号来区分值,因为属性值可能包含任何的分隔符:空白符,等号或者是尖括号。
这里有一些例子:
<font face="Arial" size=12>
<font>标签有两个属性——face和size,他们的每一个都有一个对应值。并非所有的值都是这么简单的。看一下下面这个标签:
<input type="hidden" name="txtPara" value="He was a codeslinger, lean and nervous, with quick hands that could type or shoot with equal accuracy.">
再一次说,并不是所有的浏览器需要用引号来包含每一个属性值。再再一次,即使并不需要,你也应该强制你自己每次都添加上。我保证如果你不这样做,在你用.NET的编程生涯中一定会被引号引发某种问题。这里有两种HTML标签的版本,一个有引号,一个没有:
<input type="text" value="This is my value.">
<input type=text value=This is my value.>
在浏览器中,这些标签会以文件输入控件的方式来显示——等价于Windows应用程序里面的当行文本框。第一个输入控件包含了文字“This is my value”。但是第二个版本只包含一个单词“This”。这是因为,没有引号,浏览器必须退到下一个分隔符来标记属性值的终结。在这种情况下,下一个分隔符就是空格。浏览器会忽略接下来的三个单词“is”,“my”和“value”,因为这三个单词不能被认为是关键字,而且他们也不是符合格式的属性——因为他们既没有等号也没有值。
你可以使用单引号或者双引号来分割属性值;换句话说,下面两个是完全相同并且是合法的:
<script language='VBScript'>
<script language="VBScript">
你能使用三种方法来在值中包含引号:
You can embed quotes in a value three ways:
把外面封装的引号变成相反的类型;例如,value="Mary's socks"或者是value='The word is "important"'。
把在里面出现的引号输入两次:'value=Bill''s cat'。
使用实体(Entity)——实体就是那些可以代替不合法的字符的字符。有很多特殊的实体;例如,能表达引号的实体是六个字符"。但是在大部分浏览器中,你都可以使用实体来显示任何字符——包括Unicode字符。方法是这些实体要包含一个(&#),一个你想要显示字符的二进制值,以及一个分号。你也可以使用16进制值但是需要放置一个x在#之后。所以,单引号(ASCII值39)的实体值是',或者使用16进制值,'。因此,另一种嵌入单引号的方法是"value='Bill's cat'"或者是16禁止的"value='Bill's cat'"。
更多HTML语法
属性值有最复杂的语法。对于HTML的其他语法都很直接。
空白符是可选的 除非你特意包含一个标签来强制浏览器包含空白符,否则浏览器会忽略它。当把语句"Welcome to Visual C# and ASP.Net!" and "Welcome to Visual C# and ASP.NET!"提交给浏览器,二者会在屏幕上显示完全相同的结果。
大小写是无关的 HTML解析器会忽略大小写,所以你可以用大写(<FONT>)或者小写(<font>)来写标签。已经说过,你应该尽量让大小写统一(是的,XML是大小写敏感的)。使用小写字母有两个好处。第一,W3C会标准化兼容XML版本的HTML为小写,叫做XHTML。第二,小写字符需要更少的击键次数。撇开兼容性不说,选择随便大小写的一种并且让它们尽量一致。我一般是用小写字符,但是我承认,我并没有完全保持大小写一致。
标签的顺序是重要的 一个封装标签必须完全封装任何一个内置标签。例如<font size=12><b>This is bold</font></b>是一个不合法的HTML语法因为你必须在<font>标签前关闭粗体标签<b>。合法的方式是这样的<font size=12><b>This is bold</b></font>。
这些简单的规则会帮助你写出完美的HTML。
在写起始标签的时候写上结束标签 例如不要指望先写<html>之后在某个时刻补上</html>。一定要同时写出它们,并且在标签之间插入内容。
使用小写标签 因为很容易输入
使用模板 模板是提前写好的文件,你只需要插入内容即可。因为模板已经包含了需要的标签,所以会为你节省很多时间。
适当缩排标签 在你的编辑器中把Tab或者是缩排的值设小一点——我发现3个空格就很好。这会让缩排足够明显,又不会让那种比较长的行滚出屏幕。
恰当的使用注释 在HTML中,注释封装在一个特殊的结构中。该结构以左尖括号,包括一个叹号,两个小横杠为始,以两个小横杠以及右尖括号为终:: <!--This is a comment-->。注释可以帮你理解文件的内容和布局。它们可以帮助可视化的分割段落。浏览器不会去在意注释,所以你可以在任何地方使用它们。
--------------------编程问答-------------------- 强人~~
这样看不方便, 弄成文档吧。 --------------------编程问答-------------------- 创建一个简单的页面
你一般都可以使用模板来创建一个新文件。大部分的基本HTML模板都只包含必须的标签。你需要按照需要来填充内容。把下面这些键入你的HTML编辑器,并且把它保存为template.html。
<html>
<head>
<title><!—标题 --></title>
</head>
<body>
<!—在这里输入你的内容 -->
</body>
</html>
你会看到使用这个文件是非常方便。如果你在使用一个精密的HTML编辑器,在你从“文件”菜单选择“新建”的时候,它应该会载入类似的文件。
在<title>标签中间添加标题。把注释<!--标题-->换成"HTML很容易"。把光标移动到<body>标签之后并且用你的内容替换<!--在这里输入你的内容 -->。完整的文件应该看起来很类似清单2.1。
清单2.1:HTML 很容易 (ch2-1.htm)
<html>
<head>
<title> HTML很容易</title>
</head>
<body>
<h1 align="center"> HTML很容易</h1>
<p>尽管HTML有大约100个不同的标签,你会很快发现你就使用很少几个。最重要的标签是段落标签——也就是封闭这段的标签(<p>) ; <b>粗体</b>标签; <i>斜体</i>标签(在微软产品里面的表达有些许不同,分别是<strong> 粗体</strong> 标签和<em>斜体</em> 标签);头(heading)标签; 以及在所有里面最重要的表格(table)标签,该标签可以用来生成有或者没有边框的格式化的表格。</p>
<!--<p> </p>-->
<table align="center" border="1" width="50%">
<thead>
<tr>
<th align="center">产品</th>
<th align="center">价格</th>
</tr>
<tr>
<td align="left">帽子</td>
<td align="right">$14.50</td>
</tr>
<tr>
<td align="left">靴子</td>
<td align="right">$49.99</td>
</tr>
</table>
</body>
</html>
在你输入完成之后,把它保存为一个文件,然后在你浏览器里浏览一下。为了做这件事,输入: <drive><path><filename>,drive就是你保存文件的硬盘盘符,path就是目录或者是层次化目录,filename就是文件名。在你的浏览器中,你会看到类似于图2.2显示的页面。
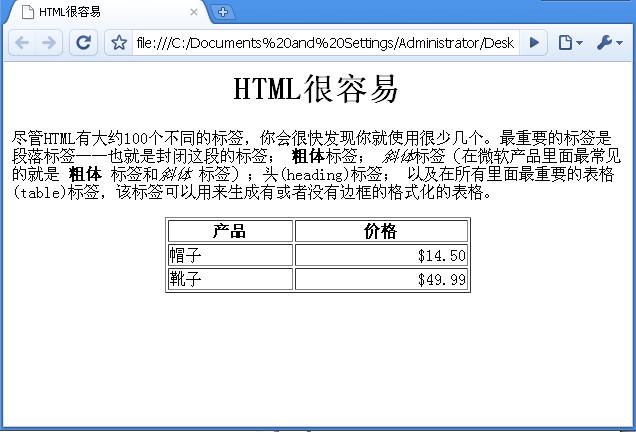
图2.2:HTML很容易 (ch2-1.htm)
当你在浏览器中看清单2.1,你应该注意到几个特点。标题出现在浏览器的标题栏,而不是文档体中。那是因为标题根本不是文档的一部分——它是页眉(Header)的一部分,这就是为什么<title>标签在<head>标签里。
如果你输入的文字和我写的完全相同,你会注意到表单中行的中断处和浏览器中行的中断处不同。你输入的每一行(尽管你可能根本没有看到)都以两个字符终结:回车和换行(ASCII值为13和10)。浏览器把他们当作泛空白符并且忽略了他们。如果你需要浏览器按照你的要求断行,那你需要使用<br>或者是断行标签来显试的指定断行位置。
注意: <br>标签几个你必须输入相应的结束标签的例外情况。结束标签</br>不是必须的(尽管你可以输入它)。然而,就算没有她你的页面工作良好,但是养成写结束标签的习惯会让你的页面对于XHTML和XML兼容。
另一种有趣的特性是断行和显示内容的屏幕区域是相关的,叫做窗口的客户端区域(Client Area)。调整你的屏幕大小,看看文字会发生什么变化。当你改变浏览器窗口的宽度时,浏览器会重新安排断行以使得文字可以恰好放置在窗口内——文字清单会获得窗口的长度。
注意: 那到底是使用什么字体呢?Serif字体,例如Times New Roman,还是非Serif字体,例如Arial?那字体大小呢?作为一个页面设计师,你应该在脑子里记得默认的字体和默认的字体大小是根据你的浏览器本身的设置来设置的,而不是你的文档本身。默认的字体和字体大小都是用户在网景和IE浏览器里面设置的。如果你想要文本按照特定的字体和大小显示,你就必须包含适当的标签或者是(最好是)层叠样式表。即便是这样,最终结果也是依赖于终端用户在他们电脑中的设置。
接下来,让我们看一下<h1>标签。它有一个叫做align="center"的属性,这个属性让浏览器把内容显示在页面的中间。还有另一种方法在页面中安排内容的布局。你可以像这样写:
<center>
<h1>HTML很容易</h1>
</center>
在浏览器中,句法结构看起来都是一样的。尽管大部分的HTML编辑器单独安排每一个元素,你还是会看到那种语法。当你要强制安排许多连续的元素的时候,<center></center>语法就会是最有用的了。在HTML4.0中,<center>标签被抛弃了但是被写成<div align="center">。再说一遍,除非一定要用老版本的浏览器,你总是应该使用较新的语法。
段落标签<p>封装了整个段落。可以通过添加一个布局标签来改变段落的布局。试一下添加align="right"属性到段落标签上,然后刷新浏览器。
小窍门: 在作出任何改变之后,你都应该刷新一下浏览器。我看过很多人抱怨说浏览器没有正确的显示他们的代码改变,但实际的问题是他们忘记刷新浏览器了。浏览器会把网页内容缓存到一个特殊的文件夹。当访问网页时,浏览器会首先检查一下缓存该网页是否可用。浏览器可以联系服务器来看一下是否有一个更新版本的该页面,但是默认是不做的。刷新浏览器会强制客户端重新发送请求,重新解析,并重新显示页面,因此,任何改变都会与上次浏览器显示的页面合并显示。你可以在大多数浏览器中配置,让它们强制检查更新的页面。那会减慢你浏览远程文件的速度,但是可以帮助你保证看到最新的版本。不管你怎样设置浏览器缓存,当你没有看到你做的改变时,你就应该刷新一下来强制更新。
<b>标签和<strong>会实现完全相同的功能——加粗字体。不同是<b>标签会显式地加粗字体,但是<strong>标签的最终显示结果并没有在HTML中指定——那依赖于显示引擎的创建者。在实际中,主流的显示引擎都是选择加粗字体。
你会发现同样的状况也发生在<i>标签上。<i>标签显式地把字体变成斜体,但是许多HTML作者会使用<em>来代替。再说一次,<em>标签的最终显示结果并没有在HTML中指定——显示引擎可以使用任何方式来强调字体。在实际中,主流的显示引擎都是选择把字体变成斜体。
你也可以使用颜色名字,例如红(“red”)或者是蓝(“blue”),最现代的浏览器会把文字显示成期望的颜色。IE和网景可以理解颜色名(尽管他们理解的颜色集是不同的)。在接下来的一章“字体和颜色”中,我会交给你使用一种浏览器无关的方式来指定颜色。
你可以使用<font>标签改变字体的颜色。注意,可以改变字体的指令是风格(<face>)指令。大部分人会误用单词“字体”(font)。另外,大小(size)属性——在清单2.1中指定为5,并不是像文字处理器中所说的磅值;它是指相对于用户选择的默认大小的字体比较值。标准的大小是从1到7,默认的是3,所以封装在标签<font size="4">Larger text</font>内的文字会显示得稍微大一点。注意,字体标签已经被抛弃了,这意味着如果不是必须,你应该避免使用它因为这个标签在未来的版本中不会被支持。然而如果你需要写底层的浏览器(很少,但是仍然在用),<font>标签仍然是需要的。所以我把它写在这里。
之后是第二段只包含一句 的段落。那意味着插入空格。开始的&以及结束的;都是必须的。有几种这样的指令,一个是对于每个非字母数字的字符。你可以使用它们来插入浏览器不能正常打印的字符,例如左尖括号(<)以及右尖括号(>),他们分别代表大于号和小于号。插入空格强制浏览器显示那一段。因为该段落不包含任何内容,所以浏览器会忽略这一个空白段落。因为那是一个空格符,所以普通的空格是没办法正常工作的。除非是个把空白符当作一个分隔符,不然浏览器总是会忽略它。之后,浏览器会把这个分隔符当作单个空格。插入空格是一个“不可见的”字符。在文本处理器中,它就是一个“硬空格”(Hard Space)。
表格标签包含三个属性:属性align="center"强制浏览器把表格显示在屏幕中间。属性border="1"让浏览器围绕每个表格放置一个可见的,一个像素的边框。属性width=50%使得浏览器在半个水平空间中显示表格(如果可能的话)。再一次,调整你的浏览器大小。你会注意到随着窗口的宽度改变,表格宽度也会改变。把浏览器窗口变到无法容纳表格那么小,因为窗口变窄了,你就可能会需要滚动才能浏览整个表格。那什么发生了呢?在某个时刻,表格不会显示在半个屏幕中。在那一刻,浏览器放弃了,并且简单的把表格显示在所剩空间的中央。当空间变得太小了,浏览器会固定住表格的右边边界。表格本身包含两个单独的部分:<thead>部分包含<th>标签组成了表格的头部分。Thead意味着表格头(Table Head)。<th>标签包含了列(Column)的名字。你不需要一个thead部分,但是如果你和<th>标签一起使用,浏览器会自动把列的名字变成粗体。<tbody>部分包含了数据。<tr>标签(表行)分割了行,同时<td>标签(表数据)根据列把行分成一个个部分(Cell)。对于和表格相关的标签而言,结束标签都是必须的,除了列名(<th>)标签,它的结束标签是可选的。
注意,你已经看过了完整的HTML文件,我会花一点时间来更详尽的解释每一个HTML元素的用途。
文本格式化
HTML使得文本格式化变得非常容易,只要你不是对文字显示太挑剔。你可以通过使用标题样式(Heading Style)来控制文本的显示,像是字体,颜色,段落以及列表。
列表样式
你已经看过了怎样使用字体标签和段落标签。HTML也包含了一些可以用来格式化符号化和编号化列表的标签。符号列表(Bulleted List)是无序列表,项目的物理顺序是不重要的。因此,在HTML中,你可以使用<ul>标签,它意味着无序列表,来创建列表。你也可以在列表的每一个项目周围放置一个<li>(列表项目)标签:
<ul>要做的事情
<li>去便利店</li>
<li>到兽医站接狗狗</li>
<li>买新电脑</li>
</ul>
当项目的顺序很重要时,你可以创建一个编号列表(Numbered List)。在HTML中,你可以使用<ol>标签,也就是有序列表来创建。你还是可以像无序列表那样使用<li>标签来罗列项目。
<ol><b>要做的事情——有序</b>
<li>去便利店</li>
<li>到兽医站接狗狗</li>
<li>买新电脑</li>
</ol>
图2.3显示了浏览器会怎样显示这两种列表。
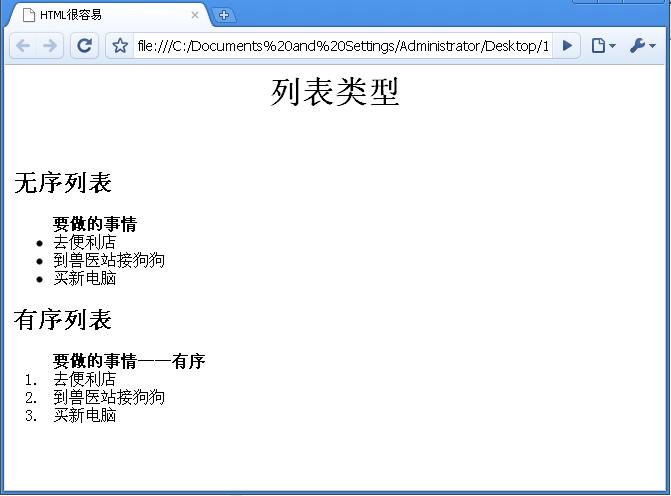
图2.3:列表类型(ch2-2.htm)
你也可以嵌套列表到一个列表中。浏览器会让从属列表比包含列表多一层缩进(见图2.4)。
<ol><b>要做的事情——有序</b>
<li>去便利店</li>
<li>到兽医站接狗狗</li>
<ul><b>记住这些条目</b>
<li>买个新狗牌</li>
<li>要一个新的跳蚤粉药方</li>
</ul>
<li>买新电脑</li>
</ol>

图2.4:嵌套列表(ch2-3.htm)
你可以为不同的目的使用不同的文本格式化方法。你可以在附件A,“ HTML快速参考”,中找到一个完整的列表。但是这里还是有一点要说。
正如你所见,浏览器会忽略断行。你可以在段落中使用<br>(换行)标签来强制换行。例如,在你的浏览器中看一下清单2.2(也看一下图2.5)。第一段不包含任何换行符,然而在第二段每行的末尾都是一个换行符。如果你缩小窗口,第一段会被调整大小。第二段也会,但是那些有换行符的地方还是会显示出来。
清单2.2:显式断行 (ch2-4.htm)
<html>
<head>
<title>显式断行</title>
</head>
<body>
<h1>显式断行</h1>
<p>
这段不包含任何的换行符。
当在浏览器中显示时,浏览器会插入换行符。
如果你调整窗口大小,浏览器会重新调整换行符的位置。
</p>
<p>
这段 <i>的确</i>包含换行符。<br>
浏览器在遇到 <br>标签时换行。<br>
当在屏幕上显示时,如果你调整浏览器大小,浏览器 <i>不会</i>重新调整换行符。<br>
</p>
</body>
</html>
</body>
</html>

图2.5:显式断行(ch2-4.htm)
我将用两个便笺来结束这章。首先,许多优秀的HTML作者为你做了大量乏味的,低层的工作。而且我也看到许多网站使用了许多高级功能来或者很炫的效果。然后,除非你完全了解了基本的HTML,你还是应该避免使用高级编辑器。问题是这些高级编辑器为你做了太多了。这本书的观点是为了让你能仅仅使用一个简单的文本编辑器就可以理解和写出HTML代码。因此,我建议知道你绝对保证你可以自己写出那些高级编辑器给你插入的内容的时候才使用他们。
第二,在你完全掌握浏览器的默认显示之前,不要试着去打败它。我保证即便是使用默认的HTML指令,你还是可以创建出非常吸引人并且功能强大的页面。高级的HTML编辑器其实会阻滞你的学习。在这些浏览器中,你可以在像素层面上指定文本和图像的放置。记住,他们并不是通过HTML的指令来完成这个放置,而是使用层叠样式表或者是嵌入式样式——我会在这章的晚些时候简单的介绍他们。
--------------------编程问答-------------------- 标题样式
HTML可以认出六种标题样式,从<h1>到<h6>。数字意味着一个层次化的标题内容的位置。就像大部分的文本处理器,数字越小,内容的层次越高。图2.6显示了在IE 5中的六种标题样式。

图2.6:六种HTML标题层次 (ch2-5.htm)
再说一次,标题的显示格式是浏览器相关的。在不同的浏览器中,标题层次也会显示不同。
HTML是一种创建结构化文档的方式。你通过像是大纲的标题层次来组织文档。顶层的<h1>可能是文档标题。本质上来说,文档所有的其他部分都是<h1>的低层。你可以用<h2>来组织主要的子层,用<h3>来组织比<h2>层更低的子层。例如,在这一章,结构化的HTML将会是这样的:
<h1>第二章:HTML基础</h1>
<h2>HTML就是标识和内容</h2>
<h3>HTML可以做什么</h3>
<h3>为什么HTML那么重要</h3>
<h3>HTML的局限性</h3>
<h2>语法:标签和属性</h2>
<h3>什么是标签?</h3>
<h3>什么是结束标签?</h3>
等等… …
注意这是一个相对弱的创建结构化文档的机制,因为在HTML中并没有指定包含在子层标签中的内容“属于”更高一次的标题。那也就是说,你不能选择<h2>标签并且同时获得<h3>标签以及和标签相关的文字。相反的,相关机制是依靠位置决定的。HTML解析器规则是说所有在一个标题层次的内容都属于那个标题层直到遇到下一个标题层。而且,浏览器不会对一个给定的标题层和更高层的内容有不用的格式化方法。对于标题层的唯一的可视化线索就是标题本身,渲染器并不会提供一个可视化的方法,例如缩进,来帮你区分在不同层次上的内容。
字体和颜色
你已经看过一个简单的使用<font>标签的例子。在这一部分,我们要更深入一些。字体标签本身是没用的,他们需要一个或者多个属性来完成对包含文字(叫做标签文字)的可视化表达。字体标签有以下的属性:
字体(face) 改变字体为一个指定的字体。如果在客户端计算机没有该字体,浏览器会使用默认的字体。你可以通过列出多个字体来增加浏览器选中相似字体的可能。例如,标签<font face="GreenMonster, Arial, Times New Roman">指定了你倾向于使用的字体依照顺序是GreenMonster(据我所知,这个不存在),Arial以及Times New Roman。浏览器会首先试一下GreenMonster。当失败了,它就会尝试使用Arial,这个字体是可以正常在Windows平台使用的。
大小(size) 改变字体大小到一个特定的大小。大小是一个数字,但是你可以使用数字来告诉浏览器应该怎么解析数字。默认的,浏览器会把字体大小默认为3。
颜色(Color) 指定了标签文字的颜色。 网景和IE都能理解一组定义的颜色集。然而,他们理解的颜色集是不同的。但是所有的浏览器都可以理解一个叫做RGB(红,绿,蓝)的颜色集。RGB颜色包含三个16进制值,他们连到一起组成了一个6个字符的字符串。典型的,你可以附加一个数字符(#)在字符串前。例如,颜色#000000代表黑色。尽管空格没有被显示,但是你可以认为字符串是原本写成#00 00 00的。前两个0代表红色部分,在这个例子中,没有红色。第二个二元组是绿色部分,第三个二元组是蓝色部分。在这个例子中,因为每个颜色部分都是0,所以最后的值就是黑色。每个部分有256个不同的值——从0到255。不幸的是,你已经把他们写作16进制值,而不是更让人熟悉的10进制。你可以阅读下面这段信息,“16进制系统和RGB颜色值”,来获取把10进制翻译成16进制的更多信息。
16进制系统和RGB颜色值
人类倾向于使用10进制,也许是因为他们有10个手指。计算机一般是使用几种其他的进制:2 进制(Binary),8进制(Octal),16进制(Hexadecimal)。在计算机术语里,16进制一般被简化叫做Hex。因为两位的16进制数字就可以表达0到255所有的数字,这等价于8位的一个字节可以表达的数字。另一种方法就是你可以认为一个字节就是2的8次幂。记住,每一个位只能够是0或1,所以计算机就是最“幼稚”的2进制。
每个字节有两个半字节(Nibble)。一个半字节有4位并且可以表示16个值——从0到15。半字节很容易翻译成16进制,因为每个16进制数都可以表达为一个半字节。正如10进制有10个数字,16进制有16个。基本数字是0到9代表最初的10个值,并且我们使用字母A到F来表示剩下的5个值。正像在10进制系统中一样,每一个数字都是10的倍数,在16进制系统中,每一个数字都是16的倍数。所以数字10是A,15是F。15之后,你需要加入一个新的16进制的数字,所以16就表示为10——意思是一个16和0个1。
看一下下面列表中的一些例子:
10进制 16进制
0-9 一样
10 A
11 B
12 C
13 D
14 E
15 F
16 10
32 20
64 40
81 51
255 FF
每个RGB颜色值是一个字节,其10进制值从0-255;因此,你可以用两个16进制位来表示值,从00到FF。为了在两个系统中互相转换,使用模运算(Modulo Arithmetic)。把你的10进制值除以16来找到第一个16进制位并且使用余数作为第二个位的值。例如,16进制表达17是11(17/16=1,余数为1)。16进制表达200是C8(200/16=12,余数是8).
考虑相反的方向,可以用最左边的位乘以16并加上最右边的10进制值。例如,B9 = ((11 * 16) + 9) = 185。
小窍门: 你并不需要学习16进制来写RGB的颜色值(尽管这会有帮助)。一个最简单的在10进制和16进制之间翻译的方法就是使用Windows的计算器附件。点击视图(View)菜单,然后点击科学计算型(Scientific)。计算器就会改变它的外表。点击10进制(Decimal)选项,然后输入一个数字并且点击16进制按钮来从10进制翻译到16进制。相反的,点击16进制按钮并且输入一个16进制值,然后点击10进制按钮可以从16进制翻译到10进制。
正如我以前提到的,<font>标签被HTML 4以及更高版本抛弃了。当可能的时候,你应该使用层叠样式表来格式化字体而不是使用<font>标签。
段落标签,Div标签以及跨距(Span)
段落标签<p>是包围在段落文字之间的块元素(Block Element)。他们可以包含“子”标签,例如文本和图片格式命令,而且他们也可以包含表格。你可以强制浏览器靠左(默认)或者靠右显示段落,或者是通过添加一个属性,例如<p align="center">,来居中显示。
Div元素,通常叫做层(Layer),是一种把你的文档分成几个部分的方式。你可以认为<div>标签是一个在段落间的手动的分隔符,就像是标题层那样。主要的不同是<div>标签是块元素。你可以通过“问”<div>标签取得所有的与<div>相关的文本和HTML信息。默认的,<div>标签就像是一个段落标签并且拥有相同的属性。例如,你也可以通过增加align="right"属性来让<div>标签的内容靠右显示。W3C之所以增加<div>标签就是为了弥补标题层在实现上的弱点。在网景中,<div>标签最初是以<layer>标签的形式实现(<layer>不被HTML 4.x或者是网景6及更高版本支持),他们的主要目的是帮助元素在Z轴上的显示。
跨距(Span)没有默认的格式。他们的主要目的是帮助你通过样式单及脚本来增加特定的格式或者是动作到比一个段落或者一个Div小的文本段中。在清单2.3中你可以看到他们的不同:
清单2.3:Div和Span实验 (ch2-6.htm)
<HTML>
<HEAD>
<TITLE>Div和Span实验</TITLE>
</HEAD>
<BODY>
<span>这是一个 Span。</span>
<span>这也是。</span>
<p> </p>
<div>
<span>这是一个 Span。</span>
</div>
<span>这也是。</span>
</BODY>
</HTML>
这个文件包含两个同样的句子“这是一个Span。”以及“这也是。”的两个拷贝,每个句子都被Span标签围绕。唯一的不同是在第二个拷贝的第一个Span(也就是缩进的那行)是<div>标签的一部分。如果你在浏览器中看一下清单2.3,应该是如图2.7显示:

图2.7:Div和Span实验 (ch2-6.htm)
当你在操作用文档对象模型(DOM)写的页面的单个元素时,你会看到更多的<span>和<div>标签。大部分流行的HTML编辑器,例如Frontpage和Dreamweaver,大量使用<span>和<div>标签来隔离在块标签中拥有对Z轴控制的文档元素。如果你使用HTML编辑器,你会看到大量的这种标签。
<body>标签
<body>标签可以接受很多能够帮助提升你页面整体显示的属性。这一点可以通过让你控制页面背景颜色及边缘,甚至是添加背景图片才实现。为了添加背景颜色,使用bgcolor属性。例如,下面的<body>标签可以把页面的背景颜色变成粉红色:
<body bgcolor="#FC00B3">
下面是<body>标签的属性和值列表:
alink为选择的超链接准备一个RGB或者是命名颜色值。当用户把输入焦点和鼠标移到链接上时,超链接就会被选择并被激活。
background 指向一个图片的URL。
bgcolor 为页面指定一个RGB或者是命名颜色值作为背景。
bottommargin(仅限于IE) 指定页面的下边际为一个特定值,该值指定像素的数目。
leftmargin(仅限于IE)页面的左边际为一个特定值,该值指定像素的数目。
link 为没有激活的超链接准备一个RGB或者是命名颜色值。
rightmargin(仅限于IE)页面的右边际为一个特定值,该值指定像素的数目。
scroll 控制页面上是否显示滚动条。
text为页面上的文字准备一个默认的RGB或者是命名颜色值。
topmargin(仅限于IE) 指定页面的上边际为一个特定值,该值指定像素的数目。
vlink 为访问过的超链接准备一个RGB或者是命名颜色值。
bgsound 指向一个声音文件的URL。声音文件会被自动下载并在下载完毕之后自动播放。在浏览器可以自动播放前需要完全下载声音文件使得bgsound在现实中不是特别有用。
使用字体和颜色创建格式化的页面
没有什么像是学习一门技术这样。试着创建一个页面,该页面需要包含一个100像素的左边际以及100像素的右边际,需要使用至少三个标题层,一个列表,并且需要配合相应的字体颜色和格式化指令。对于该目的,清单2.4包含一个实例文档。
清单2.4:实例HTML页面 (ch2-7.htm)
<html>
<head>
<title>DOM简介</title>
</head>
<body bgcolor="#ffffc0" leftmargin="100" rightmargin="100">
<font size=3>
<h1 align="center">文档对象模型 (DOM)简介</h1>
<h2>在网景和IE浏览器中的不同实现
<p><font size=2 face="Verdana">
万维网联盟(W3C)把各种可以出现在HTML页面的元素当作一个<i>对象(Object)</i>。DOM的目的就是这样的使得你能用程序访问页面上的各种元素。
</font></p>
<p><font size=2 face="Verdana">
不幸的是,对于DOM,两种最常用的浏览器有不同的实现。
微软的IE浏览器有最完整的实现。从版本3开始,网景和IE浏览器把表单和输入元素都交给脚本语言。从版本4开始,IE开始处理几乎所有的标签,元素,或者是程序化控制。为了实现这个,微软增加了一些新属性到每个标签,里面最重要的就是可以指定页面中每个元素的ID。相反,网景(版本4)的实现相当有限。
</font></p>
<h2>DOM对象</h2>
<p><font size=2 face="Verdana">
在你理解DOM对象之前,你需要从大概念上理解对象。一个对象就是一个“真正”对象的计算机模拟实现。
</font></p>
<h3>对象属性和方法</h3>
<p><font size=2 face="Verdana">
球是一个好例子。球有物理属性——它(通常)是圆的,有颜色,有弹性,在某种程度上,所有的球都共享这些属性。你可以把这些属性表达为所有球的通用属性——而且你也可以用变量表达这些属性。
</font></p>
<p><font size=2 face="Verdana">
球可以是操作或者是操作主题。例如,你可以滚球,扔球,或者是让球弹起来。这些操作叫做“方法(Method)”。所有的对象都有属性和/或方法。属性是对象的内置特性,而方法是操作。在实际中,这两者间是有概念上的重叠的。例如,球的颜色很明显是个属性,但是球的速率可以被实现为一个方法或者是属性,例如"球的速率为0." (属性)或者"把球的速率变成100。",这就等价于扔球(这到底是个属性<i>还是</i>方法呢?)。
</font></p>
<p><font size=2 face="Times New Roman">
下面的列表显示了球对象的属性和方法。
</font></p>
<h3>球的属性</h3>
<font color="#0000ff">
<ul>
<li>形状</li>
<li>颜色</li>
<li>直径 (两侧)</li>
<li>直径 (前后)</li>
<li>直径 (头脚)</li>
<li>材质</li>
<li>弹性</li>
<li>表面材质</li>
<li>位置</li>
<li>速率</li>
<li>方向</li>
<li>加速度</li>
</ul>
</font>
<h3>球的方法</h3>
<font color="#0000ff">
<ul>
<li>滚</li>
<li>谈</li>
<li>撞击</li>
<li>移动</li>
</ul>
</font></h2>
</font>
</body>
</html>
这个页面太长,所以不能在一个图像中显示,但是在www.sybex.com可以见到。为了在你的浏览器中看一下该页面,可以到CSharpASP\Ch2目录中双击ch2-7.htm文件。
--------------------编程问答-------------------- 在你的网站中包含图像文件
没有图像是非常难想象一个网站的。想象一个非常简单的方法使用HTML来插入图像到页面中也是非常难的。只需要花一点精力,你就可以把图像和文字融合甚至是让文字环绕图像。在接下来的讨论中,你的所有的图像都以图像标签为始。
图像标签
为了在页面中放置一个图像,你需要使用<img>标签之后跟一个属性src=URL,URL可以指定你想要发送的文件。有趣的是,服务器不会和页面的其他部分一起发送图像文件;相反,浏览器会解析页面中的HTML和文字,然后开始从服务器请求相关的内容,例如图像。那就是你为什么经常会看到页面加载,然后图像就会在几秒钟之后出现。
有时候,图像并不会按照你浏览器窗口顺序来显现。浏览器会顺序请求图像,但是服务器可能不会按照相同的顺序响应请求。当你设计页面的时候,这也就是你需要记在心里的。
对于<img>标签,有几个可选属性。width="数字" 和 height="数字"属性分别指定了图像的宽度和高度。两个属性都是可选的。如果没有这两个属性,浏览器会按照图像的原始大小显示。可选的标签就是——可选的。如果你想要或者不管它们,你就可以包含它们。但是,就像是大部分选择一样,你可以选择任何一种操作。因为浏览器的默认行为是把你的图像按照原定大小显示,大部分时候,不管宽度和高度属性看起来是一个好选择——尤其是对小图像。当你包含宽度和高度属性是,在浏览器向服务器请求图像文件之前,它会为图像保存一个区域。当你不包含宽度和高度属性时,浏览器会放一个“图像丢失(Missing Image)”图标在图像位置。这样就有一个问题。如果浏览器知道图像将有多大,它就可以完成页面图层的设计。如果浏览器不知道,直到从服务器获得图像之后,图层的计算才能完成。它可能必须移动已经显示好的文字和图像。最终的结果就是当你没有包含可选的宽度和高度属性时,页面加载会更慢。
大部分在HTML页面中的图像是图像交换格式(GIF)或者是联合图像专家组(JPEG)文件,因为它们是高度压缩的,所以比起他的图像文件更小。使用其他文件格式并没有技术障碍——尽管没有一些图书的显示器,客户端不能显示它们。网景可以显示GIF(读作“jiff”)以及JPEG或者是JPG(读作“j-peg”)文件。IE增加了位图(BMP)文件。两个浏览器都接受插件或者是ActiveX扩展,这些可以为其他文件格式提供显示器。例如,Macromedia的Flash格式需要下载Flash阅读器。
并不像标准的可执行程序,缺少资源并不会太影响浏览器——它会简单的忽略确实的资源。如果资源一般是可见的,浏览器会在那个位置显示一个图像缺失图标。
除了资源,宽度和高度属性,你可以指定在包含标签中怎样排列图像。例如,对于大部分图像的包含标签都是<body>标签,所以,如果你在<body>标签中靠左排列图像,图像会在页面的左边缘排列图像。如果你在一个表格单元中放置相同的靠左排列的<img>标签,图像会显示在表格单元的左边,而不是页面的左边。
除了你期望的右和左值,排列属性可以使用一些不太常用的值。表格2.1显示了一些特定排列关键字的结果。
表格2.1:表格排列属性
排列属性 结果
ABSBOTTOM 把图像放置在相对于文字的最低的点。ABSBOTTOM在最长文字下降的底部。
ABSMIDDLE 把图像放置在文字的中间。
BASELINE 把图像放置在文字的基线处。
BOTTOM 把图像放置在包含标签的底部。
LEFT 把图像放置在包含标签的左边。
MIDDLE 把图像放置在包含标签的水平中间。
RIGHT 把图像放置在包含标签的右边。
TEXTTOP 把图像放置在文字的顶部。
TOP 把图像放置在包含标签的顶部。
BORDER 决定边缘宽度的数字。默认宽度是1。0意味着没有边缘。
HSPACE 决定图像左右边缘以及任何围绕项目的空间的数字。
ISMAP 该属性没有值。当图像被认为是服务器端的图像映射时,它可以存在。图像映射(Image Map)是一个或者多个像是定位标记(Anchor Tag)的图像——他们会超链接到当前文档的定位标记,另一个文档,或者是另一个URL。服务器端的服务映射很少使用在当前的浏览器上。当用户点击一个作为服务器端图像映射的图像时,浏览器会发送点击事件的鼠标坐标到服务器。你必须使用ASP或者是CGI脚本来初始化一个动作来处理点击事件。
USEMAP 这个属性把<map>标签的名字当成一个值。它指定了浏览器应该使用在<map>标签中定义的触摸区来决定是否用户点击在图像的超链接区域。<map>标签定义了一个客户端图像映射。
VSPACE 决定图像上下边缘以及任何围绕项目的空间的数字。
在页面中放置图像
默认地,浏览器会把图像放在页面中被解析的位置。然而,一些动作会改变默认的位置。例如,如果页面中第一个标签是<img>标签,图像会显示在浏览窗口用户区域的左上角。用户区域是窗口中显示内容的位置。它出去了边缘,状态条,以及任何其他工具条。任何图像后的文字会显示在图像的右下角,因为先把图像放置在页面上把基线移动到图像的底部(见图2.8)。

图2.8:默认的图像安排 (ch2-8.htm)
你可以通过添加排列属性来改变<img>标签;例如,<img src="someURL/topImg.gif" align="right">会把图像放在用户区域的右上角。你可能会想,在文件中的图像后添加文字会折叠(Wrap)文字,所以文字会在图像后的第一行开始并且在图像底部显示。但是浏览器不是这么显示文件的。改变图像的显示到右端显示,浏览器会把文字放在用户区域的左上角(见图2.9)。

图2.9:靠右排列的图像 (ch2-9.htm)
如果你回去添加align="left"属性到显示在图2.8(ch2-8.htm)的文件中,文字会放置在图像的右上角而不是右下角。你应该花些时间在实验对于<img>标签的各种属性设置,因为结果不会总是比预料的那样。
在图像周围折叠文字
HTML不会让你很容易的在图像两端折叠文字。你可以通过添加align="left"或者是align="right"属性到<img>标签围着图像的三个边折叠文字 。
如果你想要在文字中插入图像——例如,一个图标或者是小图片——你可以通过把图像放在中间(Centering)来放到文字中间(见图2.10)。

图2.10:行中的图像 (ch2-10.htm)
背景图像
IE和网景都支持背景图像。你可以在<body>标签中设置背景图像作为属性:
<body background="http://myserver/mysite/someimage.gif">
页面中的图像会显示为背景图像,这也意味着任何其他的内容会显示在图像上面——换句话说,图像的Z轴顺序是0。例如,我已经在图2.11的图像上中放置了一个列表。

图2.11:背景图像
关于图像你第一个应该注意到的事情是它被放置了多次。那是因为浏览器把整个图像平铺到背景上。平铺意味着浏览器把图像放置在左上角并且沿着页面的水平方向重复放置图片多次。当到达最右边,它会在第一张图片下面的最左边开始继续放置——就像是人在读书时用的方式。浏览器会平铺图像因为这门技术想要使它很容易的显示背景图像。如果你需要一个单个图像,你应该显示放置。
IE也可以用单个图像作为水印(Watermark)显示。水印不是平铺的。就像是论文中的水印,它就是一个被放置一次或者多次的图像,通常是垂直或者水平居中。就像是一个标准的背景图像,水印的Z轴序也是0。所以所有的其他内容都会被放置在水印之上。
超链接简介
超链接(Hyperlink)就是万维网中的“网”。超链接赋予你增加和控制用户从你的应用程序的任何地方浏览和跳转的能力。超链接是Ted Nelson的智力,他把人类知识的整个集合想象成超链接内容。它的Xanadu项目就是为了这一目标而努力了很多年。现在,互联网正在快速的实现它的目标,尽管是以一种非结构化的方法。
超链接的目的是提供给人们一种从一个位置,话题,或者是知识颗粒移动到一个相关的位置,话题,或者是知识颗粒。例如,如果文档在一个电子表单中,我会希望对于每个和ASP相关的术语,每个对于那个术语的定义,以及每个HTML标签,每个那个标签的定义,都有一个超链接。通过这个定义,我希望对于一个或者多个例子有个链接,任何相关的术语,以及也许其他相关的术语,例如SGML, XML,或者是W3C标准文档。
当一个用户在一组链接中移动,或者是遍历,浏览器会维护一个能够让用户以相反的顺序访问已访问过页面的历史列表。现代的浏览器通常会维护这个列表到几个星期。大部分浏览器允许你配置历史列表保存的时间。它们也通过把整个历史作为一系列链接从而允许你一次回复多步。
你可以把整个链接集合作为一个网络,但是在这本书中,我更倾向于你把他们想象成一个应用程序。在一个应用程序中,和网站不同,你有特定的目的。相反,在一个网站中,或者是互联网中,用户可以简单的浏览而没有任何特定的目的。因此,在应用程序中,链接既是一个信息链接器,也是一个应用程序动作引发器。例如,一个表单中的按钮是一个链接——但是它的功能是引发应用程序的一个动作。一个浏览按钮是一个链接,但是它并不需要链接到相关信息——它可以连接到一个菜单,或者是它可以退出应用程序。
定位标记
在HTML中,从一个位置链接到另一个位置的主要方式是定位符,或者是<a>标签。这是一个非常简单的机制,它使用URL在两个位置之间移动。你可以指定一个URL作为href的属性值:
<a href="http://myserver/mysite/mypage.htm">
到我的页面
</a>
浏览器会把这段跟着一个开放的定位标记的文字变成一个链接,所以,在前面的例子里面,链接唯一可见的部分就是“到我的页面”。浏览器会持续把<a>标签之后的文字当成链接的文字知道遇到结束标签</a>。在起始和结束标签之间的所有部分都是定位标记,包括空格(有时候浏览器会忽略空格)都是一个链接文字。
有两种类型的定位标记:链接(Link)和书签(Bookmark)。他们的功能是完全不同的。链接是作为超链接触发器的定位标记——当你点击链接时,它会启动或者是触发链接动作。书签是作为链接终点的定位标记。你可以跳到一个书签,但是书签是不可见的,而且你不能点击他们。浏览器会把包含链接的定位标记变成有下划线和颜色的文字——默认是蓝色。在用户访问过链接目标后,浏览器一般会改变链接的颜色。
为了创建一个标签,你必须给定位标记一个名称(name)属性:
<a name="Bookmark1">
你可以跳转到一个书签,无论是不是在一个文档。基本上来讲,书签就是一个跳转到文档某个位置而不是最顶上的方法,一般来说,跳转到文档最顶上是默认的链接目标。为了跳转到相同文档的不同位置,你需要写一个如下的链接标签:
<a href="#Bookmark1">
注意:在href属性值最前面的符号(#)。该符号通知浏览器链接地址是一个书签而不是文档。你也可以通过增加#符号以及书签名到URL的末尾来链接到另一个文档的书签:
<a href="http://myserver/mysite/mypage.htm#Bookmark1">
你可以看到很多页面会在正上方设置可以跳转到页面下半部分标签的链接。典型的,你也会看到在每个标签都有一个可以跳回到顶端菜单的链接,这样可以保证在度过那部分之后,可以跳回到菜单来选择一个不同的部分。这样设置比设置一组互相连接的页面有更多好处。一个有菜单的长文档会花更少的时间创建,并且只需要一次对服务器的请求。单个长文档也能更容易的打印。另一方面,因为那必须滚动文档,所以读长文档也更难。
清单2.5是一个包含菜单以及内部书签的例子。分隔段(<p> </p>)就是为了在页面中放置足够的空白来保证页面需要滚动——在普通文档中,你不会需要他们的。在浏览器中,菜单页面看起来就像是图2.12显示的那样。
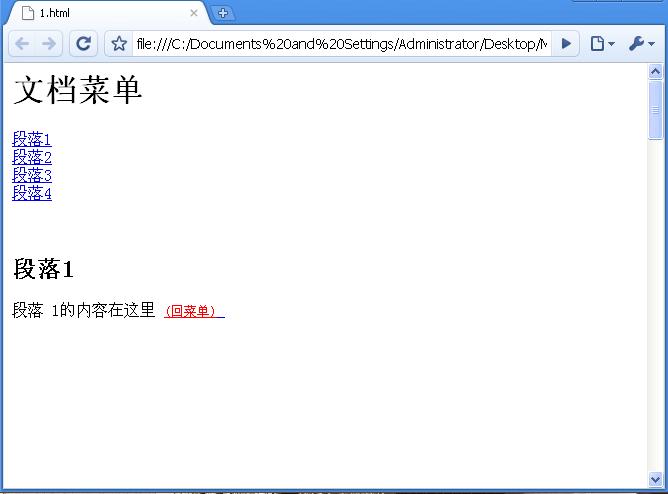
图2.12:有几个段落的菜单页面
清单2.5:有几个段落的菜单页面 (ch2-12.htm)
<html>
<head>
<title></title>
</head>
<body>
<a name="Menu">
<h1>文档菜单</h1></a>
<a href="#Bookmark1">段落1</a><br>
<a href="#Bookmark2">段落2</a><br>
<a href="#Bookmark3">段落3</a><br>
<a href="#Bookmark4">段落4</a><br>
<p> </p>
<a name="Bookmark1">
<h2>段落1</h2></a>
段落 1的内容在这里
<a href="#Menu"><font size="2" color="red">
(回菜单)</font>
</a><br>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<a name="Bookmark2">
<h2>段落2</h2></a>
段落 2的内容在这里
<a href="#Menu"><font size="2" color="red">
(回菜单)</font>
</a><br>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<a name="Bookmark3">
<h2>段落3</h2></a>
段落 3的内容在这里
<a href="#Menu"><font size="2" color="red">
(回菜单)</font>
</a><br>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<a name="Bookmark4">
<h2>段落4</h2></a>
段落 4的内容在这里
<a href="#Menu"><font size="2" color="red">
(回菜单)</font>
</a><br>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
</body>
</html>
为了让你可以看到一个不同的风格,清单2.6包含一个格式为一组链接页面的多重选择问题。
清单2.6:一组链接页面 (ch2-13a.htm- ch2-13e.htm)
<!--******************************************************
* 文件(ch2-13a) 包含多个选择的问题。 *
* 每个分散器(Distractor)都是一个链接到其他页面的链接, *
* 这些页面包含分散器的反馈。 *
**********************************************************-->
<html>
<head>
<title></title>
</head>
<body>
<p>下面哪一个 <EM>不是</EM>合法的定位标记类型?</p>
<ol>
<li><a href="ch2-13b.htm">指向其他文档的链接。</a>
<li><a href="ch2-13c.htm">指向其他文档特定位置的链接。</a>
<li><a href="ch2-13d.htm">指向前面文档的链接。</a>
<li><a href="ch2-13e.htm">指向浏览器中回退按钮的链接。</a>
</li></ol>
<p>选择你的答案。</p>
</body>
</html>
<!-- *****************************************************
* 文件 (ch2-13b)包含第一个(不正确的)分散器的反馈。 *
**********************************************************-->
<html>
<head>
<title></title>
</head>
<body>
<p>不正确</p>
<p>你的选择:“1. 指向其他文档的链接。” 那是一个合法的标签类型。
点击 <a href="ch2-13a.htm">继续</a>重试。</p>
</body>
</html>
<!-- *****************************************************
* 文件 (ch2-13c)包含第二个(不正确的)分散器的反馈。 *
**********************************************************-->
<html>
<head>
<title></title>
</head>
<body>
<p>不正确</p>
<p>你的选择:“2.指向其他文档特定位置的链接。”那是一个合法的标签类型。
点击 <a href="ch2-13a.htm">继续</a>重试。</p>
</body>
</html>
<!--******************************************************
* 文件 (ch2-13c)包含第三个(不正确的)分散器的反馈。 *
**********************************************************-->
<html>
<head>
<title></title>
</head>
<body>
<p>不正确</p>
<p>你的选择:“3. 指向前面文档的链接。” 那是一个合法的标签类型。
点击 <a href="ch2-13a.htm">继续</a>重试。</p>
</body>
</html>
<!--******************************************************
* 文件 (ch2-13c)包含第四个(正确的)分散器的反馈。 *
**********************************************************-->
<html>
<head>
<title></title>
</head>
<body>
<p>正确</p>
<p>你的选择:“4. 指向浏览器中回退按钮的链接。” 不是一个合法的标签类型。
</body>
</html>
如果你在浏览器中看看这组页面,你会首先看到问题(见图2.13)。
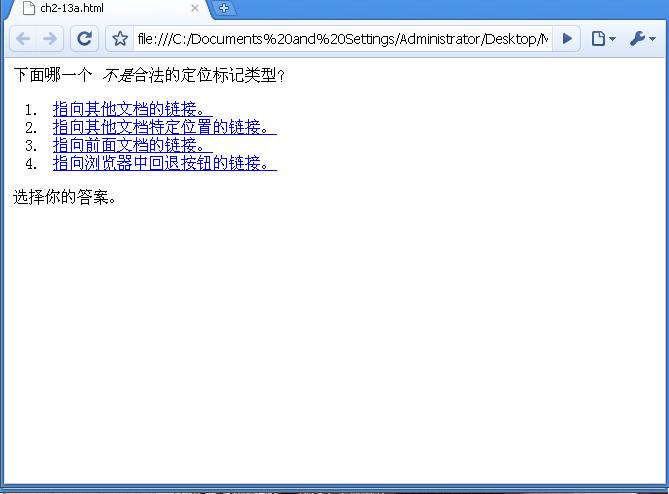
图2.13:多重选择屏幕 (ch2-13a.htm)
在你点击每个分散器的时候,你会看到类似于图2.14的页面。我不会把它们都显示在这里,因为你可以自己下载代码并在浏览器中浏览。图2.14显示了在你点击第一个分散器之后发生的事情。
图2.14:多重选择的反馈 --------------------编程问答-------------------- 牛人 翻译完整理成电子书吧。。。 --------------------编程问答-------------------- 定位标记和图像
你不能局限在文本链接上;你也可以使用图像作为链接源。例如,你可以使用定制的图标代替简单的文字链接。用户可以点击主页图像而不是“主页”这两个字。使用图像你可以让你的页面看起来更你好。使用图像创建超链接,你可以在图像标签周围放置定位标记:
<a href="http://myserver/mysite/mypage.htm">
<img src="http://myserver/mysite/home.gif" border=0>
</a>
默认的,浏览器会在可点击的图像周围放置一个边界。边界的颜色继承了页面的链接颜色。如果你不想要边界的话,像上面那个例子那样使用属性border=0就可以了。
格式化表格
表格包含行和列。因为浏览器会忽视空白,包括Tab,在HTML中你通常会使用表格来显示必须用空白来分隔的项目。注意这并不要求使用版本4或者更高版本的浏览器——你可以使用绝对位置来强制项目显示在特定的像素位置。然而,即便是在现代浏览器,表格也比显示柱状数据更有用。
<table>标签包含几种其他的标签来用于分隔行和列。表格有三个部分——表头(Header),表格体(Body),以及页脚(Footer)。表头和页脚行是“固定的”行——他们不能滚动(尽管在大部分浏览器中是这么做的)。表头和页脚是可选的;为了创建一个合法的表格,你并不需要包含它们。如果你包含表头和页脚的任何一个,那你也必须包含表格体。表格也可以有标题(<caption>)标签。浏览器也可以把标题放在第一行之上。表格的边缘设置并不会应用于标题。另外,IE中的表格包含<colgroup> 和 <col> 标签,这些标签可以帮助简化表格格式化过程。<colgroup>标签定义了一组列,<col>标签为列组定义了每个具体的列。
表格,表格行,表格数据标签
表格以<table>标签为始。你使用表格行标签(<tr>)来分隔行,用表格数据标签(<td>)来分隔列。下面的HTML描述了一个简单的两行两列表格:
<table>
<tr>
<td>
行 1,列 1
</td>
<td>
行1,列 2
</td>
</tr>
<tr>
<td>
行2,列 1
</td>
<td>
行2,列 2
</td>
</tr>
</table>
警告:要小心的关闭所有的表格标签。一些浏览器,例如IE,会帮你关闭标签而且表格可以正常显示,但是有些不能,表格根本不会显示或者是不会正确的显示。微软的文档说对于大部分文档元素,结束标签都是可选的,但是这只适用于IE浏览器。所以规则就是:不要依赖于显示引擎来关闭标签;永远都显式地关闭所有的标签。
正如你在前面的代码段上看到的,表格可以包含任意数目的行,对于每一行,表格可以包含任意数目的列。它不会特别好看——看起来就像是两个选项卡式的列(见图2.15)。

图2.15:实例HTML表格 (ch2-14.htm)
幸运的是,你可以添加属性到表格标签中来控制它的定位以及显示。表格标签的属性值可以应用于表格所有的行和列除非你用针对单个行,列或者是单元的属性值来代替它。下面的列表包含最常用的属性值;你可以在附录A中找到其他的。
align 该属性有三个值:左,右,或者是中。它控制了页面中表格的水平放置。
background 该属性,就像是针对<body>标签的background属性,接受指向一个图像文件的URL。浏览器会在Z轴上显示该图像,其他所有的数据都会显示在背景图像之上。
bgcolor 该属性会用HTML颜色值来控制整个表格的背景颜色。你也可以针对单个行或者列重写背景颜色。
border 该属性会接受一个整数值来控制围绕表格和每个单元的边缘的控制。默认值是0:没有边缘。
cellpadding 该属性会接受一个整数值来控制两个单元的内容和边缘之间的空间。
cellspacing 该属性会接受一个整数值来控制两个单元之间的空间。
cols 该属性在表格中指定列的数目。它显著的增大了浏览器显示表格的速度。没有这个属性,浏览器必须先解析整个表格来获得行中列的数目,但是没有这个属性,浏览器可以立刻开始显示行。
height 该属性会接受一个整数值来通知浏览器要显示表格区域的最终高度。就像是cols属性一样,包含height会显著的增大了浏览器显示表格的速度。你可以指定像素高度或者是针对可见用户区域的比例高度。
width 该属性会接受一个整数值来通知浏览器要显示表格区域的最终宽度。就像是cols和height属性一样,包含height会显著的增大了浏览器显示表格的速度。你可以指定像素宽度或者是针对可见用户区域的比例宽度。
如果你把这章开始时候的表格例子拿来,排列它到页面中间,指定宽度和高度,加上标题,加上边缘,并且填充上单元,最初的两行应该看起来是这样的:
<table border="1" align="center" cellpadding="3" cellspacing="2" width="60%" height="80%">
<caption>格式化的实例表格</caption>
如果你在浏览器中看一下这个修改过的表格,它看起来应该是图2.16这样。

图2.16:有边界的简单表格 (ch2-15.htm)
正如你在例子中看到的那样, <tr>标签指定了表格的行。你可以在<tr>标签中使用align已经bgcolor属性。<tr>标签也可以使用valign标签来控制行中每个单元内容的水平排列。可能的值是baseline,bottom,center,以及top。
<td>标签接受align,background,bgcolor以及valign属性。另外,<td>标签也接受colspan和rowspan属性。colspan和rowspan属性的值是整数。它们指定了单元扩展的行和列的数目。当你有一个行包含不同数目的列时,你会需要这个属性。例如,如果你想要添加第三个行到图2.16的表格中,该行只包含一个行,并且希望添加一个是其他行单元高度两倍的单元,你可以如下指定该单元:
<tr>
<td colspan="2" align="center" valign="center">
这是一个两倍宽度的单元格,内容居中。
</td>
</tr>
<tr>
<td rowspan="2" width="50%" align="center" valign="center">
这是一个两倍高度的单元格,内容居中。
</td>
<td width="50%" >普通高度的单元格</td>
</tr>
<tr>
<td width="50%" >普通高度的单元格</td>
</tr>
增加了新行之后,表格如图2.17所示。

图2.17:使用 colspan和rowspan属性的表格 (ch2-16.htm)
表头,页脚标签
你可以把表格分为三个主要的功能部分——表头,一个或者多个表格体,以及一个页脚。表头和页脚的主要目的是当用户打印横跨多页的表格时,在每页复制表头和页脚。对于没有边界的表格,你可以通过把内容放置到多个表格体中,从而在表格体中使用水平线分隔成几个部分。你还是可以让表格只有一个表头和一个页脚。
为了定义表头,使用<thead>标签。表头可以有多行。你也可以通过使用<th>表头标签而不是<td>标签来自动用粗体显示表头。
在表格中,你可以有多个表格体(<tbody>)。每个<tbody>标签定义了表格体的一部分。默认的,即使你不显式地定义,每个表格也有一个表格体。浏览器会用水平线分隔多个表格体。
你可以使用页脚标签(<tfoot>)来定义页脚。页脚可以有多行。没有相应的页脚标签<tf>来对应表头中的表头标签。然而,你可以在页脚中使用<th>标签代替<td>标签来让页脚格式化为粗体。
使用表格来安排布局
因为浏览器使用它的内部规则来安排显示和放置内容,你不会很容易去控制一个特定的项目显示在哪里。在更现代的浏览器中(版本4及更高),你可以使用绝对位置来强制项目放置在一个特定的位置。在早期的浏览器(版本3及更低)以及少数不流行的浏览器中,你仍然需要使用表格在屏幕中来安排及放置项目。
第二个——我想对于大部分的目的来说,也是最重要的——原因使用表格来安排布局,甚至是在现代浏览器中,是你可以使用比例而不是像素来指定表格和单元格的宽度。这个很重要是因为几个正在使用的不同的屏幕分辨率是:: VGA (640 x 480),Super VGA (800 x 600),以及 XGA (1280 x 768)。例如,通过增加width=60%属性到一个表格标签,浏览器就会根据客户端浏览器的分辨率来按照客户区域60%的比例显示表格。当然,在不同的屏幕分辨率下,文字会以不同的方式折叠,但是你可能知道页面会怎样显示给不同的用户,因为表格会占据屏幕相同的比率而不管用户使用的到底是VGA还是XGA显示器。相反,使用基于像素的定位方法会不管屏幕的宽度和高度来设置项目的位置。
这有一个例子。假设我想要增加一个定制的数字图片而不是数字来作为清单2.6中的分散器,但是我仍然希望人们可以点击每个分散器的文字来回答问题。我可以使用两个链接而不是一个全文字的链接。第一个定位标记可以包含定制的图像作为分散器。第二个定位标记可以包含文字作为分散器。两个链接可以转到相同的页面。我会如下改变第一页:
<html>
<head>
<title></title>
</head>
<body>
<p>下面哪一个 <EM>不是</EM>合法的定位标记类型?</p>
<a href="ch2-13b.htm"><IMG SRC="images/1.gif" border="0"></a>
<a href="ch2-13b.htm">指向其他文档的链接。</a><br>
<a href="ch2-13c.htm"><IMG SRC="images/2.gif" border="0"></a>
<a href="ch2-13c.htm">指向其他文档特定位置的链接。</a><br>
<a href="ch2-13d.htm"><IMG SRC="images/3.gif" border="0"></a>
<a href="ch2-13d.htm">A 指向前面文档的链接。</a><br>
<a href="ch2-13e.htm"><IMG SRC="images/4.gif" border="0"></a>
<a href="ch2-13e.htm">指向浏览器中回退按钮的链接。 </a><br>
<p>选择你的答案。</p>
</body>
</html>
使用图像映射
图像映射(Image Map)类似于图像链接除了你可以在图像上定义一个或者多个可点击区域。可点击区域“对应于”一个书签或者是URL。例如,每个地图可以显示每个州的概况,并且每个州都是一个到不同位置的链接。为了创建完整的针对每个州的图像映射,你必须创建每一副图像,然后使用绝对位置安放图像以使得图像可以适当地被安放。或者说(更简单的),你可以使用一个图像,然后沿着州的边界创建可点击的区域。
有两种图像映射:服务器端映射(Server-side Map)以及客户端映射(Client-side Map)。服务器端图像映射告诉浏览器:当用户点击图像,浏览器应该把点击点的坐标发送给服务器。一个服务器端程序(例如ASP页面)必须判断这个坐标是不是在一个合法的点击区域。如果是,超链接到相应的页面。直到3.x版本的浏览器出现,服务器端图像映射是唯一的图像映射方式。当你想要用脚本把图像分到许多长方形区域时,或者是当你的客户可能在使用老版本浏览器时,服务器端图像映射仍然是有用的。然而,用户的每次点击都会让浏览器发送信息到服务器端去处理,所以服务器端图像映射一般来说是对资源的非高效使用。
注意: 在这一章,你不会看到服务器端图像映射,而仅仅是客户端图像映射。在稍晚些时候,我会重新提到服务器端图像映射,当我们在第II部分中讲到Request对象时。
客户端图像映射定义了图像的可点击区域并且URL关联到客户端HTML的每个区域。客户端接管了处理用户鼠标点击的负担,因此避免了在客户端和服务器端的往返通讯。
图像映射是如何工作的
对于计算机而言,屏幕像是一个每个单元都是一个像素的桌子。每个像素有一个列数和一个行数。第一个像素是在屏幕的左上角,列0,行0。通常,你会使用两个整数值,中间用逗号分隔,来指定像素;例如0,0或者是100,100。另一种想象屏幕的方式是,就像是你们在数学课上记得的那样,是一个x-y网格。每个像素的列数(第一个数字)是x值,行数(第二个数字)是y值。任何点都出现在第四象限里面,也就是x轴以下,y轴以右的区域。
你使用相同的方法指定图像中的像素来让它们显示在屏幕上,除非像素位置被指定为从图像左上角的偏移量(Offset),而不是屏幕的左上角。所以,如果你有一个图像,一边是100像素,你也想要把那个图像放到位置100,100。那么图像的左上角的像素就是100,100。但是在图像里面,你需要指定像素就好象相同的位置是0,0一样——也就是图像本身的第一行和第一列。
你可以使用左上角和右下角来定义一个长方形。我将使用分号来分隔每个像素。例如,被图像盖住的长方形是100,100;199,199。通过这两个像素,你可以推导出图像区域的四个角分别是左上100,100,右上199,100,右下199,199,以及左下100,199。
如果你想要把100平方像素的图像分成四个部分,你需要把它们定义为长方形——假如这样的话,每个区域就是每边50个像素。那些你将要使用的点是针对于图像左上角的偏移量。所以从左上角开始顺时针移动,第一个长方形将是0,0;49,49,第二个是51,0;100,49,第三个是51,49;99;99,最后一个是0, 50; 49, 99。
你不必局限于长方形,你也可以定义圆形以及多边形。正如你可以想象的,为密闭区域或者是不规则的多边形找出真正的像素值是很困难的。幸运的是,你几乎不用自己计算值了。有许多图像映射编辑器,它们可以让你可视化的跟踪和画出映射区域的边界。
创建客户端图像映射
你可以使用<map>标签来创建客户端图像映射。例如, 清单2.7显示了用于创建描述前一章客户端图像映射的HTML文件——图像被分为等大小的小区域,每一个都是一个指向其他文档或者是书签的超链接。
清单2.7:客户端图像映射例子 (ch2-19a.htm)
<html>
<head>
<title>客户端图像映射</title>
</head>
<body>
<map name="fourSquares">
<area shape=rect coords="0, 0, 49, 49" href="ch2-19b.htm#upperLeft" border="0">
<area shape=rect coords="51, 0, 100, 49" href="ch2-19b.htm#upperRight" border="0">
<area shape=rect coords="51, 49, 99, 99" href="ch2-19b.htm#lowerRight" border="0">
<area shape=rect coords="0, 50, 49, 99" href="ch2-19b.htm#lowerLeft" border="0">
</map>
<IMG SRC="images/bluesquare.gif" usemap="#fourSquares" border=0>
</body>
</html>
<map>标签是一个包含一些列<area>标签的部分,每一个<area>标签定义了一个图像的可点击区域。map标签本身不必和使用坐标的<map>标签在相同的文件中。让我们使用美国地图作为例子,你可以在一个文件中定义包含每个州可点击区域的<map>标签,然后从多个页面中引用那个文件,每个都可以包含同样的图像映射。通过这种方式,如果你想要改变一个可点击区域,你只需要改变包含图像映射的一个文件即可。
<area>标签定义了链接的目标URL以及图像的可点击区域。对于一个给定的图像,你可以创建多个<area>标签。每个<area>标签必须有一个shape属性以及一个包含用逗号分隔的坐标串的coords属性。shape属性拥有三个可能的值:
circ或circle
poly或polygon
rect或rectangle
当shape属性值是circ或circle,coords属性需要三个值:原点的x轴和y轴坐标以及半径。当shape属性值是poly或polygon,coords属性包含一系列定义多边形的x轴和y轴坐标值。当shape属性值是rect或rectangle,coords属性包含长方形左上角和右下角的x轴和y轴坐标值。
创建图像映射的工具
有很多商业级别的图像映射创建工具,而且他们以一种相似的方式工具。你把图像加载到图像编辑器,然后绕着图像的热点画一个长方形,圆,或者是多边形。图像映射编辑软件会输出图像映射的HTML,有时仅仅是映射定义,但是更通常的是链接标签以及映射定义。
即便你只需要在你的图像上创建一个长方形的热点,图像映射工具可以节省你大量的时间。
有三种流行的资源;其他的大致相当。注意,没有一个解决方案是免费的,而且我不会推荐你什么。你可以从互联网上下载MapEdit以及JImage-Map。
Microsoft FrontPage 98或 FrontPage 2000
MapEdit (shareware)
JImageMap (Java solution)
理解框架
为了理解框架,你需要及时回到Windows的开始。一个窗口是一个包含位图(Bitmap)的内存区域——也就是一个像素的长方形区域。每个程序都“包含”一个或者多个窗口,并且每个窗口或者是一个最顶层窗口或者是一个子窗口。所有的窗口都是桌面窗口的子窗口——所谓桌面窗口,你可以把它想成屏幕本身。
例如,在Windows中打开任何程序并且在屏幕中浏览。你会看到一个标题栏(Title Bar),窗口框架(Window Frame),以及一个客户区域(Client Area)。你会看到其他的附加选项,例如包含按钮和其他东西的工具栏,以及状态栏。每个项目都是一个独立的窗口。每一个都有特定的属性,例如高度,宽度,以及背景颜色。如果你打开多个窗口,想象一下你的屏幕。如果你想象一个程序就像是打开栈中的项目,总有一个窗口在最顶上。Z-order的值会控制栈中每个窗口的位置。最顶上的窗口(活动窗口)的z-order的值是0。所有其他的窗口会出现在活动窗口之下并且拥有一个更高的z-order值。除非你最大化所有的窗口,每个窗口都会出现在屏幕上的些许不同的位置,意味着每个窗口都有自己的区域。
程序的主窗口是最上面的窗口。每个项目,例如工具栏按钮,是一个子窗口。子窗口,尽管他们有自己的控制权,他们都会随着或者不随着他们的父窗口出现。如果你最小化程序窗口,所有的子窗口也会随着从屏幕上消失。
--------------------编程问答-------------------- 先放到这里吧。谢谢大家这么热情的反馈。知道自己水平有限,所以翻译的时候难免会有些许问题,如果哪位大牛发现了,请通知我。不胜感激。:)
主要是每次只能连续回帖3次比较讨厌。 --------------------编程问答-------------------- LZ加油 我来给你断楼 --------------------编程问答-------------------- 哥们 弄成文档 上传到csdn上 让我们下着看多省心呀 不过还是谢谢你 --------------------编程问答-------------------- 搞成文档吧,支持楼主 --------------------编程问答-------------------- 非常感谢! --------------------编程问答-------------------- 强大的lz --------------------编程问答-------------------- 我觉得楼主的翻译方向应该在初中级特别是刚入门程序员上,翻译那些技术先进(比如现在是VS2010,就别翻译VS2005的了),又讲得深入浅出的书。
我好书标准是:最好是概念解说性语言少,指导说明性文字多(用在代码解释上)。 --------------------编程问答-------------------- 厉害!帮顶!
--------------------编程问答-------------------- 楼主,牛人
你可以打成压缩包放在上面供大家下载不? --------------------编程问答-------------------- 支持。 --------------------编程问答-------------------- 在浏览器中,你会使用框架的概念来定义子窗口。框架(Frame)是主窗口的子区域,但是你会把每一个框架当作是一个完整的单独的浏览器。每一个框架可以独立的访问一个页面。对于计算机而言,每个框架是一个拥有大部分浏览器能力的子窗口除了它是从属于最上层的浏览器窗口。框架必须被安放到最顶层浏览器窗口的屏幕区域,而且当你最小化最顶层窗口的时候,他们也需要跟着最小化。你可以把框架想象成一种把浏览器窗口划分成不同大小的窗口的简单方式。
框架不能自己存在——你必须使用一个叫做框架集(Frameset)的概念来定义他们。一个框架集必须定义在自己的页面——你不能定义一个框架集并且把它的内容(而不是一个<noframes>标签)放到一个简单的HTML文件中;然而,你可以在一个简单页面中定义多个框架集。框架集是不可见的——它是框架的包含标签。框架集可以包含一个或者多个框架或者是框架集。框架本身通常是可见的,尽管不可见框架也有很多用处。例如,你可以使用包含客户端脚本的不可见框架来控制页面中的其他框架。你可以使用<frameset>标签来定义框架集,使用<frame>标签来定义框架。例如,为了创建一个把浏览器的客户区域分成两等分的框架的框架集,你可以如下定义一个<frameset>标签:
<frameset rows="50%, *">
<frame name="topFrame" src="top_1.htm">
<frame name="bottomFrame" src="bottom_1.htm">
</frameset>
对于那些不支持框架的浏览器(现在已经很少了),你可以增加一个<noframes>标签。
<frameset rows="50%, *">
<frame name="topFrame" src="top_1.htm">
<frame name="bottomFrame" src="bottom_1.htm">
<NOFRAMES>你需要一个支持框架的浏览器来浏览这个网址!</NOFRAMES>
</frameset>
那些支持框架的浏览器会忽略<noframes>标签。其他浏览器会显示<noframes>标签里面的内容,因为它就是不出现在tag之间的HTML的内容——记住浏览器会忽略掉它们不支持的标签。
你可以根据像素或者是比例定义框架的大小。注意你可以在值中使用星号(Asterisk)来定义最后一个框架,其意义是“可用区域的所有余下部分”。换句话说,我可以如下定义框架rows=”50%, 50%”,结果可以是一样的。星号标记在你使用像素定义框架的时候非常有用。一般来说,你可能不知道浏览器的宽度,所以准确的定义最后一个框架非常难。例如,假设我想要垂直的把屏幕分成两份。左边的框架包含一系列链接,而且我想要它是200像素宽。我想要在右边框架上显示内容——但是我不知道右边的剩下部分是440像素(VGA),600像素(Super VGA),或者是1080像素(XGA).因此,我可以使用星号如下定义框架集:
<frameset cols="200, *">
<frame name="leftFrame" src="left_1.htm">
<frame name="rightFrame" src="right_1.htm">
</frameset>
你不能在同一个框架集内同时使用行(rows)和 列(cols)属性,但是你可以嵌套(Nest)框架集来实现相同的效果。例如,下面的代码定义了一个垂直分隔成两等分的框架集。框架集还包含了第二个框架集,这个框架集可以把右边的框架水平的分为两个相等的框架(见清单2.8)。
清单2.8:嵌套框架集 (ch2-18a.htm - ch2-18d.htm)
**********************************************************
* 这个文件 (ch2-18a.htm) 包含了框架集定义 *
**********************************************************
<html>
<head>
<title>嵌套框架集</title>
</head>
<frameset cols="50%, *">
<frame name="leftFrame" src="ch2-18b.htm">
<frameset rows="50%, *">
<frame name="rightTopFrame" src="ch2-18c.htm">
<frame name="rightBottomFrame" src="ch2-18d.htm">
</frameset>
<noframes>你需要一个支持框架的浏览器来浏览这个网址!</noframes>
</frameset>
</html>
**********************************************************
* 这个文件 (ch2-18b.htm) 显示了左边框架 *
* 其他文件 (ch2-18c.htm和ch2-18d.htm) 除了 *
* 标题和内容不同其他都完全一致 *
**********************************************************
<html>
<head>
<title>ch2-18b.htm</title>
</head>
<body>
这是文件ch2-18b.htm
</body>
</html>
在浏览器中,清单2.8看起来像是图2.18。
图2.18:嵌套框架集 (ch2-18a.htm - ch2-18d.htm)
框架的优缺点
框架的主要优点在于它们可以独立显示内容并且能够可视化的分隔内容。你可以在一个框架里面定义一个链接,该链接可以在另一个框架中显示内容或者是引发一个动作而不需要重画整个屏幕。
另一方面,框架的另一个不太重要的优点在于你可以创建可重定义大小的框架。用户可以拖拽框架边缘来增加或者缩小框架的可视区域。这个特性非常有用。最简单的看到这个效果的方法(如果你使用的是IE)就是点击浏览器工具栏上的“搜索”按钮并且启动搜索。你可以拖拽搜索框架的右边缘来改变搜索和内容窗口的相对大小。
框架的主要缺点在于他们很难创建和控制。为了创建如前面清单显示的两个框架的屏幕,你必须创建三个页面:一个包含框架集定义,另外的每个框架一个页面。
框架的另一个缺点是它们需要很长时间来显示。浏览器向服务器请求框架集需要一轮的通讯。每个框架的内容显示需要至少一次的额外通讯。因此,显示两个框架的内容需要三次通讯,只要那个页面没有其他的框架。
最后,框架通常需要一些使用JavaScript的客户端编程,或者是VBScript,如果你使用的是IE。例如,如果一个用户点击框架中指向一个对象的链接——例如一个按钮或者是一个链接——在其他的框架中,你必须保证目标对象真的存在,不然用户将会收到一个脚本错误信息。直到页面加载完成,目标才会出现。当页面仍然在加载时,用户的行为是引起脚本错误的通用原因。因为使用框架的主要原因就是在一个框架中有指向其他框架中对象或者动作的操作。这类问题非常普遍。
我不准备在这本书中花大量时间解释客户端编程,因为它主要是讲服务器端编程的。然而,我可以告诉你,找到基于框架的JavaScript脚本的错误远比找到服务器端C#代码的错误要难得多。除了我所列出的问题,如果你已经对于客户端脚本很熟悉,框架可以是一个极其有能力的组织内容的工具。
怎样避免框架
如果你不使用框架,你必须不停重复相同的信息——就例如一系列链接——在一个页面中。大部分服务器拥有实现这个的机制;在IIS中,你可以使用包含文件(Include Files)来在页面中放置内容。一个包含文件就像是听起来那样——是一个指向其它文件的引用,指向的文件就是服务器“包含”的用以响应的文件。服务器会根据包含文件的内容来替换内容。例如,如果你想要在每个页面的底部放置一个版权通告,你可以创建一个包含版权通告的包含文件。你可以在每个内容页面放置一个指向你的页脚文件的引用。对于浏览器而言,响应会像你显式地写在每个HTML文件页脚那样来显示。换句话说,浏览器并不在乎(也不知道)是否响应包含包含一个还是100个文件只要文件是合法的HTML文件即可。
类似于包含文件,你也可以使用表格来在屏幕的特定区域来安排元素。在使用绝对地址来安排元素之前,表格是最普通的安排内容的方式。
控制元素位置
有两种在屏幕上放置内容的方法。第一种方法使用CSS的层叠样式表,而且也是现今所知的最简单的方法。 尽管我并没有介绍CSS(我会在这章晚些时候的“层叠样式表”一章来具体描述),我承诺这么技术非常简单,以至于你并不需要CSS的知识来使用它。第二种方法是使用表格和透明图像的混合方法。我将要分别介绍每种方法。
警告: 绝对位置的技术只适用于支持CSS的浏览器。
使用CSS来控制元素位置
首先,一个警告:绝对位置的技术只适用于版本4或者更高版本的浏览器,并且不幸的是,网景浏览器和IE的语法和方法有些许不同。网景6以及IE 5.x两者都能比早期的浏览器更好的支持CSS,尽管它们有些许不同。IE把屏幕中的每一个元素——每一段,每一个按钮,每一个字体标签——当成是一个对象。因此,每个你到现在看到的标签,除了我列出来的,都可以接受其他的几个属性。一个这样的属性是style属性。有很多值可以应用于style。在这一章,我们只是使用和位置相关的属性:position:absolute。
为了在IE中放置一个对象,你需要添加style属性,把position设置为absolute,并且指定你想要放置对象的像素位置。例如,为了在点50,50显示图像,你需要如下设计图像标签:
<img src="image/bike.gif" style="position:absolute; left:50; top:50">
这种使用style的方式叫做“内联(Inline)”,因为你在标签里面指定——换句话说,在和代码的同一行。style属性的值,就像是其他的属性值,也是一个字符串。在字符串内,你可以指定多个style值。你可以使用分号来分隔设置的每一个部分,你也可以使用冒号来分隔设置值和设置名称。例如,句子“Hello World”被安置在点100,100。
<div style="position:absolute; left:100 top:100">Hello World</div>
控制Z序位置
使用style,你可以控制元素的z序。所有浏览器中可见的元素都有一个z序值。z序值高的元素会出现在低的元素之上。在标准HTML中,在HTML流中元素的位置决定了它的z序位置。换句话说,HTML流末尾的元素会出现在流之前的元素之上。CSS支持z序值来控制每个元素的z序位置。例如,为了把文字“Hello World”放在自行车图像元素的顶端,你可以在清单2.9中如下实现页面。
清单2.9:控制z序位置 (ch2-20.htm)
<HTML>
<HEAD>
<TITLE></TITLE>
</HEAD>
<BODY>
<div style="position:absolute; left:100; top:100; z-index:0">
<img src="images/bike.gif" border=1>
</div>
<div style="position:absolute; left:100; top:100; z-index:1">
<b><font size="5" color="blue">Hello World</font></b>
</div>
</BODY>
</HTML>
值为1的z序值强制浏览器把文字放在图片上面,该图片拥有z序值0。现在,你可能还是没有明白,因为当我第一次看到的时候,我也是这样。知道那一刻,我还是必须设置表格背景为那个图片以保证图片可以出现在上面。
CSS也支持相对位置,在这种情况下,浏览器会决定元素针对于它的父元素的位置。你可以使用像素或者使用比例,使用正值或者负值,来定义绝对或者相对位置。只要可能,我最喜欢使用比例来指定位置。如果你使用比例,你会把你的页面元素从依赖于客户端分辨率的情况下分离出来。同时,显示的元素也会随着浏览器大小的改变而响应的改变位置。
例如,在清单2.10中,<span>标签包含的文字“I’m Here!”被放置在上面,同时也在它的父标签<div>的左边。
清单2.10:绝对和相对位置 (ch2-21.htm)
<html>
<head>
<title></title>
</head>
<body>
<div style="position:absolute; left:100; top:100; z-index:0">
<img src="images/bike.gif" border="1" WIDTH="227" HEIGHT="179">
</div>
<div style="position:absolute; left:100; top:100; z-index:1">
<b><font size="5" color="blue">Hello World</font></b>
<span style="position:relative; left:-100%; top:-100%; z-index:2">
<b><font size="5" color="red">I’m Here!</font></b>
</span>
</div>
</body>
</html>
图2.19显示了清单2.10是怎么样被显示在浏览器中的。

图2.19:绝对和相对位置 (ch2-21.htm)
使用表格控制元素位置
你可以使用表格来实现相似的结果,尽管会花费更多的时间并且不是很精确。通过改变表格单元的宽度和高度,你可以大致把元素放到你想要放的位置。例如,为了把一个图像放置到点100,100,你可以创建一个2列,没有边缘,4个单元格的表格。通过让最左上的单元格变得99像素高,99像素宽,你就可以保证右下的区域开始于100,100。
<table cols="2">
<tr>
<td width="99" height="99">
</td>
<td>
</td>
</tr>
<tr>
<td width="99" height="99">
</td>
<td>
<img src="images/bike.gif" border="1" WIDTH="227" HEIGHT="179">
</td>
</tr>
</table>
我可以通过设置背景属性来把文字放到图像的上面。图2.20显示了结果。我增加了边框到表格上并且把一些文字加到最左上的单元格里面以此清楚的显示。
图2.20:使用表格控制元素位置 (ch2-22.htm) --------------------编程问答-------------------- 我地天。。。
你可以联系出版社,联系作者做出版了。。 --------------------编程问答-------------------- 顶个~~楼主强人 --------------------编程问答-------------------- 楼主是个有心人! --------------------编程问答-------------------- 不错呀 满实用的 --------------------编程问答-------------------- 使用透明图像控制元素位置
你现在被限制在使用单元背景图片的方法上。你只可以赋予<td>标签的align和valign属性如下的值:left,right,center,以及top,bottom,center。然而,你可以使用一个小技巧来更准确的放置元素。
记住,使用<img>标签的width和height属性你只能够控制图像的宽度和高度。那个属性意味着你可以使用一像素宽度的图像并且把它按照任意方式改变宽度和高度。 因此,你可以使用透明图像来强制其他的内容放置在它的右边或者下边。清单2.11显示了这门技术。我把文字的颜色改成了白色以使得在图像上方显式得更清晰。
清单2.11:使用透明图像控制元素位置 (ch2-23.htm)
<head>
<title></title>
</head>
<body>
<table border="1" cols="2">
<tr>
<td align="center" valign="center" width="99" height="99">
This cell is <br>100 pixels wide
</td>
<td>
</td>
</tr>
<tr>
<td width="99" height="99">
</td>
<td align="left" valign="top" background="images/bike.gif" WIDTH="227" HEIGHT="179">
<img src="images/transparent.gif" width="50" height="50">
<b><font color="white" size="5">Hello World</font></b>
</td>
</tr>
</table>
</body>
</html>
层叠样式表
层叠样式表(CSS)实在是太复杂的主题,因此在这本书中很难详尽解释。所以我只会在这一章简单地介绍一些基本知识,并且希望能够激起你以后学习CSS的兴趣。一旦你了解了基本知识,那么你就可以引用CSS来提高你的能力。CSS从在一个或者多个网站中控制元素的可视性进化而来。例如,如果你公司的市场部决定所有的公用文档必须使用Garamond字体,你怎么才能简单的做出改变并且保证你对所有的文字都做了相应的改变?一种方法是搜索文档中每一处文字,然后使用<font>标签来指定被包含的都是Garamond字体——但是,这实在是耗时并且容易出错。如果你能够只用一次指定元素的显示方法,然后这种改变可以“传承(Cascade)”下去就好了。
层叠样式表可以做什么
CSS技术允许你很容易的做全局的改变,例如那些在前面描述的。一个层叠样式表定义了元素类型的属性。样式表定义出处现在<style>标签的内部——通常放在文档的<head>部分。这种style定义是一个嵌入式样式表,因为它被嵌入在文档内部。CSS类型包含如下的能力:
你可以定义应用于所有元素类型实体的style类型。
子元素“继承(Inherit)”了它们父元素的style类型。
你可以使用其他的样式表或者是内联style类型来重载(Override)继承的类型。
你可以引用样式表——style类型定义不一定要出现在每一个文档中。
例如,你可以通过定义<body>标签的CSS样式类型来改变文档中的所有文字的字体:
<style type="text/CSS">
body {font: 12pt Garamond;}
</style>
这个style类型包含一个选择器(Selector),一个body,以及一个规则(Rule) {font: 12pt Garamond;}。规则指定了选择器中文字将会是12号的Garamond字体。一个包含这样规则的文档中的所有文字都会是Garamond字体。
使用样式来控制显示
要看一看CSS是怎么使用的,输入或者是拷贝清单2.12的代码到文件中,然后在你的浏览器中打开文件。注意,你的浏览器会用默认的字体来显示——一会儿你就会改变这个。
清单2.12:层叠样式表例子 (ch2-24.htm)
<html>
<head>
<title>层叠样式表例子</title>
<!--<style type="text/css">
body {font: 14pt Garamond;}
</style>-->
</head>
<body>
<h1>层叠样式表例子</h1>
<h2>注意如下文字的字体和大小。</h2>
<p>这是一个简单的HTML文件。文件的开头部分,有一个层叠样式表。当<style>标签被注释掉的时候,你的浏览器会用默认字体显示文字。当你去掉<style>标签的注释时,文字会显示为14号Garamond字体(如果你的电脑中安装了Garamond字体)。
</p>
</body>
</html>
现在重新打开文件,并且移除包围<style>标签的注释标签。保存文件,并且刷新你的浏览器。你应该可以看到屏幕的改变。图2.21和2.22显示了没有样式表的文件和样式表生效的文件的区别。两个文件都使用清单2.12中的代码,但是在图2.22中我为<style>标签移除了注释。

图2.21:没有应用样式表的文字 (ch2-24.htm)
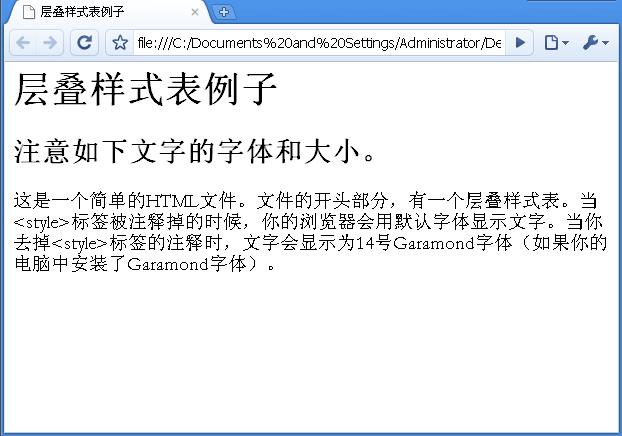
图2.22:样式表生效的文字 (ch2-24.htm)
层叠样式表的分类
有四种类型的层叠样式表。你已经看到了两种,内连(Inline)样式和嵌入(Embedded)样式。
内连(Inline)样式 元素的属性。你在一个元素标签的内部使用style="style definition(类型定义)"的属性来定义。
嵌入(Embedded)样式 是嵌入在文档<head>部分的类型标签。
链接(Linked)样式 引用外部样式表。你可以在文档的<head>部分使用<link>标签来使用它们。包含样式表定义的文档通常有一个CSS的扩展。
导入(Imported)样式 被导入到嵌入的或者是链接的<style>标签的外部样式表。你可以使用@import: url(someURL.css)命令来导入样式表。浏览器会在它处理<style>标签中显式地规则之前导入和处理导入的样式表规则。
浏览器会按照style类型规则出现的顺序来处理规则,后面出现的规则会取代前面出现的规则。相似的,应用于一个特定元素的规则会取代原本的继承的规则。
重载层叠样式表的类型
可以定义应用于所有元素类型的全局的style类型是很好的,但是当你不想要一个可以用于特定元素的全局类型时,那这个实体又该怎么办呢?你可以应用多个规则到一个元素。指定可以覆盖通用样式规则的style类型规则。例如,如果你想要body内的文字以Garamond字体显示,但是不包含标题文字,你可以在你的<style>标签中增加第二个规则:
<style type="text/css">
body {font: 14pt Garamond;}
h1 {font: 24pt Arial;}
h2 {font: 18pt Arial;}
</style>
你总是可以用内联样式属性来重载类型。例如,假设下面的<h1>标签和如上<style>标签出现在同一个文档中:
<h1 style="font: 10pt Arial">
那么,标题会以10号的Arial字体显示,因为内联规则取代了更通用的样式规则。
引用外部样式表
你不必在每个页面都包含一个样式表;相反的,你可以把样式表保存到一个独立的页面并且在每个文件中引用它。其他文件中的样式表叫做链接或者是外部样式表。例如,下面的<link>标签告诉浏览器找到被文件中href属性指定的样式表定义:
<link rel="stylesheet" type="text/css" href="mystyles.css">
你把<link>标签放到文档的head部分。
另一种方式来引用外部样式规则就是把它们导入到一个已经存在的<style>标签中。例如,假设下面的类型规则存在于一个叫做siteRules.css的文件中。
<style type="text/css">
body {font: 14pt Garamond;}
h1 {font: 24pt Arial;}
h2 {font: 18pt Arial;}
</style>
在你的文档中,你可以在<style>标签中使用@import命令来导入siteRuless.css文件中的规则:
<style type="text/css">
@import: url(siteRules.css);
li {font: 10pt Times New Roman;}
</style>
前面的<style>标签的效果就和你如下定义是一样的:
<style type="text/css">
body {font: 14pt Garamond;}
h1 {font: 24pt Arial;}
h2 {font: 18pt Arial;}
li {font: 10pt Times New Roman;}
</style>
在样式表中使用类(Class)
除了为标准的HTML元素定义style类型,你可以通过创建一个选择器的名字来定义你自己的类型。你自己创建的有选择器名称的类型叫做类(Class),因为你可以使用它们来分类元素。创建类类型的好处是你可以使用类属性来应用它们到任何元素。例如,如果你创建了一个可以把文字变红的类型,你可以简单地把它应用于你文档中的任何元素:
<style type="text/css">
.redText {color:red;}
</style>
<p class="redText">
这段文字是红色的。
</p>
<p>
这段文字是默认颜色的。
</p>
控制超链接显示
在大部分静态网站,当你点击它们链接会改变颜色,来显示你已经访问了那个链接目标。在一个应用中,如果一个人需要多次点击相同的链接来完成一个任务,那么这种表现不会是用户想要的。你可以使用CSS样式来控制你的链接显示。链接有三种伪类(Pseudo-Class),分别叫做:link,:visited,以及:active。:link伪类控制链接自然的显示,当它没有被激活(Active)(用户已经在链接上点击了)或者是访问(Visited)(用户已经浏览到链接目标)。为了组织被访问的链接改变颜色,把:link和:visited伪类设置成相同的style类型:
<style type="text/css">
a:link {color:blue}
a:visited {color:blue}
</style>
关于CSS样式的最后几句话
除了改变字体,你还可以使用CSS样式来做更多的事情;然而,在本书中,你不需要更多的经验来在例子和工程中使用它。然而,我还是劝你开始学习并且应用CSS样式。当你建立更大的网站时,CSS样式在控制和改变你的页面的显示和感觉上变得越来越重要。
总结
尽管出现了更稳定且功能更强大的HTML编辑器,我们还是处在一个开发者需要理解怎样阅读,写作以及改变元HTML的时代。当你开始操作动态生成的HTML时,你不能总是简单的替换一个值称为预先定义的HTML模板,这是非常正确的。例如,想象你有一个HTML报表模板,改模板包含了一个固定的页头和页脚。页面的中间包含报表本身。你的工作是通过查询数据库和在表格中显示结果来生成报表。
HTML模板看起来是这样的:
<html>
<head>
<title>***报表标题***, ***报表日期***
</title>
</head>
<body>
<!--定义页头的HTML应该放在这里-->
<table width="90%" align="center">
***报表体***
</table>
<!--定义页脚的HTML应该放在这里-->
</body>
</html>
作为开发者,你应该使用报表的标题和日期替换 ***报表标题*** 和 ***报表日期*** 两个占位符,并且用包含报表内容的表行来替换***表格体***占位符。你可以把这个模板加载到HTML编辑器中,但是那不会帮你,因为你需要动态的创建行。你可以要求模板开发者提供一个实例行,但是你还是需要提取内容并且在报表体中为每一个表格行复制它一次。那意味着你将要不得不使用脚本创建HTML。
这种类型的操作——合并模板HTML和动态内容——构成了基本的动态网络应用。从下一章开始,你将会详细看到什么是动态网络应用。大部分动态应用包含像是这个简单的例子的大部分操作。你操作动态网络内容越久,你就会知道学好CSS样式,绝对定位,以及DHTML会多么简化你的生活。直到你彻底熟悉这些简单的技术,用脚本创建它们——在这时,HTML编辑器是没有用的除了看一下输出——将会是非常乏味以及痛苦的工作。因此,如果你在过去没有使用过HTML,,CSS和DHTML,那么你应该花一点时间从头开始创建它们——而不使用HTML编辑器。
--------------------编程问答-------------------- LZ准备出书吧。嘿嘿 --------------------编程问答-------------------- --------------------编程问答-------------------- 你外语能力很强啊,可以转行干出版了 --------------------编程问答-------------------- 顶起,希望能做成电子档的 --------------------编程问答-------------------- 第三章:动态网络应用程序概述
综述
现在你已经有了创建HTML页面的一些经验,你应该已经有点概念哪里以及为什么HTML不足够创建应用程序。HTML用于创建信息页面是完全足够的,但是它缺少让应用程序变得——交互地——对用户有趣的性质。应用程序响应用户动作和输入。HTML文件可以相应某些操作——例如,点击一个链接或者图片的某个区域——但是那就是HTML的交互的限制。如果你想要做更多并且更多样化的相应用户行为和输入,你需要一种编程语言。HTML不是编程语言;它就是一个格式化语言。
在浏览器中有两处可以和用户交互来浏览网页。当用户改变页面时,你可以和日期交互;你可以使用运行在服务器端的代码来做这些,叫做服务器端代码(Server-side Code)。你也可以通过在浏览器本身防止代码来和用户交互。这叫做客户端代码(Client-side Code)。不幸的是,你(还)不能用相同的语言写客户端和服务器端代码因为一些浏览器只支持脚本语言——JavaScript。相反,使用经典ASP,开发者可以用VBScript实现大部分服务器端代码;现在,使用ASP.NET,大部分人选择使用C#或者是VB.NET。你还是有一个选择可以使用相同的语言实现在客户端和服务器端代码:JScript。可惜的是,Jscript是一个在.NET框架中的“第二层”语言,这意味着你会消耗大部分NET资源,但还是不能完全创建它们。
小窍门: 在将来,当.NET框架在客户端机器上变得越来越普通,你可能可以使用C#来创建只针对于IE的应用程序。
当你学习书写动态网络应用程序是,在脑中清楚客户端和服务器端代码的不同是很重要的,因为这是一个对于初始开发者很容易弄混的概念。我经常阅读注释并且自问为什么“我的浏览器不能运行ASP.NET页面!”就好象错误的原因是ASP本身一样。从浏览器的角度看,根本就ASP.NET页面这种东西——只有HTML和脚本,并且被ASP.NET页面产生的内容,被CGI脚本产生的内容或者是简单来自静态HTML文件的内容都是没有任何区别的。如果你的浏览器并不支持ASP页面,你的页面会产生对于该浏览器不合法的内容——但这并不是浏览器的错。
弄清楚动态HTML(DHTML)和动态网络页面也是很重要的。记住,DHTML是一种客户端的改变页面显示和内容的方法。在DHTML中,你可以在页面中使用脚本和CSS样式,或者是——更可能的——两者的组合,来操作元素。相反,动态网络页面是一种部分或者全部内容还没有存在于HTML表格中的页面;服务器会通过代码来创建页面。换句话说,它会动态的创建页面。这并不神秘。浏览器会期望在响应中包含文字,HTML标签和脚本的字符串,只要字符串包含合法的文字,HTML以及脚本,浏览器就会正常显示。
什么是动态网络应用程序?
动态网络应用程序是一组在一起合作从而来创作一种用户在操作一个独立程序的假象的程序。例如,想象一个典型的数据驱动的应用程序。用户登录并且选择一些参数——也许是从列表中选择一个客户名——从而来生成报表来显示该客户的购买记录。用户可以通过选择一个特定的顺序来继续钻研数据或者是选择一个用户购买的产品来看该账单的细节,例如购买地,运输方式,或者是运输日期。当你写一个像这样的独立的窗口应用程序,你可能需要计划并且把它写成一个单独的程序。程序可能有多个模块或者是多个表单和类,但是它有一个确定的开头和结尾——用户启动应用程序,用一阵子,然后关闭应用程序。当用户在使用程序时,你——作为应用程序开发者——可以控制用户能够怎样操作应用程序。
例如,你可以在核心操作时让离开 (Exit)按钮失效来保证用户不会在一个不适当的时机离开程序。在登录之后,用户不能在没有退出的情况下就重新登录并且重启程序因为在用户被授权之后,你不能再提供对于登录表单的访问。在数据输入应用程序,在填写了表单之后,用户不能退回到那个表单并且不经过一系列应用程序设计者预定义的操作来改变数据——选择一个记录然后弹出来编辑它。用户甚至不能在没有通知你的情况下退出应用程序除非关掉计算机电源。在窗口应用程序中,这种控制是已存在的——你不需要自己实现。
在动态网络应用程序中,你没有那种自由。用户操作会发生在不同于你应用程序运行的机器的另一台机器上。因此,你的应用程序不知道也不可能控制用户在做什么;你必须在不能控制这些操作的情况下来让程序正常运行。你可以使用客户端脚本来观察和控制一些用户操作,但是其他的操作会不能被脚本所控制。例如,每一个浏览器都有一个后退(Back)按钮。想象一下你有一个让用户填写的表单。用户填好后会点击提交(Submit)按钮,然后你会把数据写到数据库中。你会返回下一个页面给用户。
现在假设用户按了后退按钮。这不会向你的应用程序发送信息(因为浏览器会从缓存中加载页面)。现在用户会改变表格内容并且再次点击提交按钮。你当然不想再创建另一条记录,并且,依赖于应用程序,你可能甚至不想重写当前记录。这并不是一个不正常的现象——你需要在你的网络应用程序中计划并且限制这种事情。
这有另一种常见的情况。用户登录应用程序并且操作一会儿,但是然后他转换了想法并且在浏览器窗口输入另一个网站的URL。最后,用户会关掉浏览器并且离开机器。问题是:从应用程序角度讲,你怎样处理这个?记住,你可能已经在服务器上为用户存储了数据。那你怎么才能知道是否用户还在和你的应用程序交互呢?简单的答案就是:你不能。相反,对于核心数据,每当数据改变,你就应该把数据存储到磁盘上;对于非核心数据,在一段特定时间后,你可以抛弃它——这个时间的值可以针对用户和应用程序独立设置,叫做HttpSessionState.Timeout,通常它有一个更短的名字,叫做Session.Timeout。
最后,网络应用程序和标准的可执行程序间有一个主要的区别。在关掉浏览器并且离开之前,假设在当前的应用程序中,最后一段的用户给当前页面加上了标签。很久之后(在Session.Timeout发生之后),用户会登录并且点击该书签。那你的应用程序该如何相应呢?再者,这是一个极其平常的并且你必须预料到的问题不然你的应用程序一定会有位呢提。不像是标准应用程序,你没办法直接控制这问题——你不能组织用户创建数据并且组织用户在之后任何时间访问它。然而,你可以控制在你的应用程序收到无法预料的请求时该如何处理。例如,你可以直接把用户转到应用程序的第一页。如果你的应用程序非常友好,你应该在用户重新登录时就恢复用户的状态。
在这章的开始,我提到网络应用程序是一组程序,不是一个程序。那是因为在一个事务应用程序中,就像是网络应用程序,你不能依赖传统的数据存储技术来创建一个有粘性的应用程序。相反,你可以再细想一下,每一个都不是连续的。当你使用C#网络应用程序,你会学着把动态网络应用程序看作是一系列浏览器和服务器的事务。编写单个事务处理程序是非常直接的。让单个应用程序表现得像是一个大的整体的一部分是非常有挑战性的。
什么是数据驱动的应用程序?
你应该经常听到“数据驱动站点(Data-driven Site)”这个名词——我已经在这章使用过它。那它到底是什么意思呢?难道不是所有的应用程序都是数据驱动的么?因为所有的程序不都是从服务器下载数据然后把它发送到浏览器么?是的,但是这无关紧要。数据驱动的应用程序从数据源或者是外部数据源为用户提供数据。那意味着应用程序必须可以读(通常是写)到外部数据源的数据并且提供数据验证(Data Validation),数据缓存(Data Caching)以及数据翻译(Data Translation)的需求。
另外,数据驱动的应用程序通常会随着时间增长。即使是维护一个到实事通讯(Newsletter)的订阅列表(Subscriber)的应用程序也必须仔细计划和实现以保证它可以不仅仅是可以操作最开始的小数据,也可以操作积累了几年的数据。写一个操作100个记录的应用程序相对简单,但是写一个能操作100或者100000条记录的应用程序就比较难了。当你允许多个用户同时操作时,应用程序的复杂性会更加增长的。尽管这本书不准备提到所有在创建数据驱动应用程序时遇到的所有问题,你还是会看到怎样设计并且实现数据应用接口,并且你将会使用ADO.NET和SQL SERVER在外部关系数据库中来创建,传输和更新信息。
我为什么需要使用HTML模板和CSS?
正像你已经发现的那样,如果你想要重复地创建相同类型的表格,你就需要不停的重复创建相同类型的HTML页面。并且,一种帮助你设计粘性好的网络应用程序的方法就是仔细地设计用户接口以使得你需要对每个页面分别处理。你可以通过为你的“破”数据创建模板来实现。把用户接口(也就是模板)和数据分离开来需要自己计划,但是这也使得你的网站很容易被更新和维护。
例如,当你创建一个企业网络入口(Corporate Web Portal),你可能决定把部门列在页面最上面,每一个都以下拉菜单的方式实现。你可以把HTML,事务处理代码以及数据放到应用程序的每个页面,但是当一个部门增加了一个题目或者是你的公司分隔或者组合部门时,那又该怎么办呢?如果你把代码放到每个单独的页面,你必须改变每一个页面。这是一个典型的从小开始然后逐渐增长的例子。开发者,可以使用HTML编辑器或者是文字编辑器手动的维护20-30个页面,但是当页面增长到200或者是300页面时,就不可能这样维护数据了。
对于这个问题的答案(以及对于很多其他的编程问题)就是提供一个间接的层来把最顶端的菜单代码放到单独的文件中。IIS支持#inlcude命令,这个命令可以用另一个文件的内容来替换命令本身。例如,假设文件topmenus.asp包含菜单的HTML代码以及客户端脚本。除了把.asp文件中的内容拷贝到你应用程序的每个页面,你只需要在每个页面放置一行命令。#include命令写作HTML注释。服务器不会理解命令而会忽略它们,然后把它们发送到浏览器,同时浏览器也会忽略因为它们是注释。例如,下面的代码会让IIS把topMenus.asp的内容插入到每个页面:
<!-- #include file="topMenus.asp" -->
在#inlcude命令中,文件topMenus.asp必须和请求页面在一个目录中。另一个能让你引用服务器任何位置的文件的格式是:
<!-- #include virtual="/includes/topMenus.asp" -->
代码中的关键字virtual告诉你在网络服务器上目录包含一个虚拟路径。
让这个类比再进一步,公司端口的设计者会遍历所有页面,移除菜单的代码和数据,并且用#include命令指向的另一个文件来替换原有文件,该文件包含所有需要的功能。但是然后(你可以猜到),有些事情变了。市场部发布了一个备忘录要求所有的商业公司通讯必须使用Verdana字体。当然,端口必须立刻改变因为它变成一个公司基础信息的可视化部分。作为一个端口开发者,你会有一个问题。你该怎么改变HTML页面中的所有myriad字体的标签?有个问题。应该说很难写出一个搜索和替换(Search-and-Replace)的代码来发现和改变所有别人设置的字体。
在这个发生之前,在第一时间做出计划避免这个问题。使用CSS样式表,为你的应用程序创建一组类style类型。你应该避免使用内联样式甚至是嵌入样式,除非必须如此。使用链接或者是导入样式表。就像是你在第二章“HTML基础”上讲到的,你可以在文档的<head>部分使用<link>标签来链接样式表;例如:
<link rel="stylesheet" type="text/css" href="mystyles.css">
我并不指望你在心里牢牢记住这句话,事实上,我会在本书中都这么做。我会告诉你一个秘密:你的网络应用程序越“动态(Dynamic)”,你越是在.NET类,外部CSS文件,#include文件,数据库文件,以及代码中更好的封装功能,当环境改变时,你会更容易适应。在一个位置改变代码比在很多位置改变代码要更容易,更不容易出错。
客户交互
动态网络应用程序意味着内容会因为某个原因改变。一个创建动态应用程序的原因就是数据库中的数据可能会改变。但是就像是通常那样,因为你想要相应单个用户的喜好或者是动作,所以你才开发动态应用程序。每一次用户从你的网站请求页面,你可以把它想成一个交互的几乎。每一次用户输入一个字符或者是移动鼠标,就是另一个交互的机会。用户以前访问过页面这个事实也提供了一个交互的机会。例如,如果你登录www.amazon.com并且买了一本或者多本书,当你一会儿登录那个页面的时候你会发现有一点不同。Amazon的工作人员仔细地追踪客户的习惯。通过这样,他们可以预测你未来的购买行为。如果你买了一本哈利波特,经验显示你非常有可能买另一本哈利波特并且你也可能从其他也购买哈利波特的人购买书的列表中选到另一本书。这门技术叫做个性化(Personalization)。必须承认,这是个性化的一个高级例子,但是这也是一些基本的想法,例如用名字欢迎用户(“欢迎回来,琼斯先生”)或者是保存用户的习惯。
我并没有推荐你在你写的每一个应用程序中都实现个性化;我是说个性化和交互是硬币的两面。个性化的要点是增加交互。当Amazon为你提供一个列表,你非常有可能买另一本书。相似的,当在你登录网站时,应用程序保存并且应用你的喜好,你更可能使用它。我保证你登录过那种需要你提交一个很长的表格的网站。当你最后写完并且提交表格后,网站(在一个延迟之后)返回给你一个错误信息(这个信息你通常需要滚动鼠标来找到),这告诉你写错了某些值。这就是一个不好的交互的例子。而且你非常可能不喜欢这种应用。相反,如果一个应用程序可以在你输入错误时立刻告诉你,并且告诉你为什么错了,并且把光标放在错误的输入框内——当需要时,主动滚动到该输入框——这样的应用程序更可能让你对于应用程序满意。
直到最近,在浏览器中提供一个真正的交互很难,因为浏览器本身并没有让你和用户交互的资源,除了最简单的一些。然而,IE,从版本4或者5以及更高的版本开始,提供了一组类似于窗口编程的事件。你可以侦测鼠标活动(事实上,浏览器提供了mouseEnter以及mouseOut时间,这些连Windows API都没有直接提供),点击,双击,以及拖拽操作。连同DHTML,客户端脚本,以及互联网服务,你可以创建用户接口——尽管不像是窗口表格——也非常有服务性。最后,因为.NET使得和服务器交互非常方便,你可以创建不使用窗口表单的C#应用程序。
网络应用程序vs网站
尽管名词网站以及网络应用程序一般可以互换,它们还是有不同的。网络应用程序不同于网站因为他们有不同目的。人们浏览网站,但是它们使用网络应用程序来完成任务。大部分网站是充满信息的。大部分网络应用程序不是。
当你在Yahoo! (www.yahoo.com)看体育版,你不是在完成任务;你是去获取信息的。通常你心里没有特定的信息——你仅仅是浏览。有时,很难区分应用程序和网站。例如,Expedia (www.expedia.com) 是一个你可以浏览,查找旅游信息,费用和飞行的网站,但是它也是一个可以买机票的地方。Expedia是一个包含嵌入式应用程序的网站的例子。
相反,大多数商业应用程序就不那么明显。当用户登录到公司应用来填写购买表单,它对浏览并没有什么兴趣;他想要尽快并且准确地完成订单。用户的目的和其他网站完全不同。
区别是重要的,因为它会影响——或者是应该影响你怎么创建用户接口,什么辅助和错误信息你应该提供,以及在应用程序中为每个用户你应该存储多少数据。
什么是数据?数据在哪里?
动态网络程序使用和存储数据。数据大部分放在数据库中以使得你可以提供最新的数据给客户端。在动态网站中,数据可以存在于缓存的HTML文件中,平面文件中,以及,越来越多的,在XML文件中。
数据库
关系数据库是非常方便的数据仓库因为它们可以几乎可以存储任何类型的数据,从比特(Bit)值到非常大的二进制或者是文本(二进制大对象——文本或二进制数据的长序列),并且他们也提供了大量的排序和过滤服务。
要明智的选择你的数据库。例如,不要使用一个像Access的文件数据库;使用像是SQL Server,Oracle,DB2,Sybase,MySQL,或者是Informix这样的完整的关系数据库。如果你没有这些数据库的完整拷贝,你可以使用MSDE或者是个人版Oracle。这些“轻量级(Light)”版本的功能和完整版本几乎一样除了他们会限制数据库大小和同步链接的数量(MSDE只允许5个同步链接)。因此,他们非常适合小量开发者和测试者的应用程序开发。我并不推荐使用这些小数据库部署应用程序,毕竟——它们不能支持足够的用户。
HTML文件
当你可以,在某种程度上,从HTML文件中存储和提取数据,他们对于存储模板和缓存数据非常有用。例如,假如你在一个数据库中为用户列表存储了“真的”数据。你可以在每次用户请求了一个显示列表的页面,你可以运行一个提取数据的请求。这是最简单的保证你可以获得最新的客户数据的方法。这也是对用户资源的一个不太好的使用。客户列表不会那么经常改变。请求数据库来满足每个请求意味着你在使用数据库连接,服务器内存,以及网络带宽来重复地提供相同的数据。
另一种提供完全相同的精确度的但是使用更少资源的方法就是在第一次页面请求时动态创建页面,然后把结果HTML页面写到磁盘上。对于接下来的请求,你可以从磁盘提供页面。
但是等一下!一旦数据库改变,难道不是意味着页面过时了么?是的,但是记住,你在创建一个动态应用程序。如果你的应用程序就是那个改变数据库的,你可以在数据改变时刷新页面。如果其他应用程序也可以改变数据库,你可以写一个触发器(Trigger)来刷新数据,写一个改变文件,或者是在表格中改变标记,这样你总是可以读到最新的数据。如果触发器写一个改变文件的入口,你可以检查文件的时间戳来决定是否要刷新数据。如果触发器改变了表格中的标记(Flag),你可以使用一个可以返回一个值来决定是否要刷新数据的程序。不管你使用什么方法,结果就是你几乎不需要从数据库获取完整的客户列表来满足请求。
平面(ASCII)文件
这么多年来,“平面文件”,或者是ASCII文件,是一个把数据在平台和应用程序见传输的方法。许多商业应用仍然会定期地从平面文件的主框架接受数据。它们现在没有那么有用,因为有许多其他的方法,你还是可能发现把文件放在平面文件中而不是数据库表格中更容易。例如,把字符串放到应用程序文件日志文件的后面比建数据库,决定需要的域,写存储步骤,以及建立一个类以及一些类来控制读写日志更加容易,尤其是你需要写日志仅仅是为了帮助你定位程序错误。
然而,因为如此多的信息在平面文件中,他们都是动态应用程序的资源。
XML文件
XML文件是平面文件的替代。尽管XML文件比平面文件低效,因为文件中的重复的标签,他们却非常好用。你不必写代码来解析文件,决定域名和域长度,并且检查文件尾或者是行尾标记。并且,你也可以以完全相同的方法读取包含任何类型数据的XML文件——使用XML解析器。但是解析器的能力不仅仅只是把文件中连续的记录和域分隔。解析器可以提取单个记录或者是域或者是像数据库那样排序和过滤信息,以及使用可扩展样式表语言转换(XSLT),他们可以把数据从一个格式转换成另一种格式。.NET框架会广泛的支持XML,所以在本书的后面你会看到更多这些内容。
--------------------编程问答-------------------- LZ,你太强大了 --------------------编程问答-------------------- 支持! --------------------编程问答-------------------- 把原版英文书也贴出来吧
不过楼主还是很伟大的~~ --------------------编程问答-------------------- 强就一个字,我只说一次.. --------------------编程问答-------------------- 强列楼主弄个文档什么的做个链接提供下载 --------------------编程问答-------------------- 怎么能得到数据?
使用ADO.NET,C#拥有任何通用目的语言设计的最好的数据提取和控制能力。从平面文件到数据库,从XML文档到定制文件格式,你拥有对于怎么样和在哪里存取数据的绝对控制能力。当你主要考虑性能的时候,你甚至可以把数据维护在内存中。下面几部分给出了数据存取能力各类型的讲解。
ADO.NET
微软开发了访问服务器专用对象集(ADO)作为对早期应用于VB和Access的数据存取对象(DAO)技术替代。ADO是更早期的一门叫做ODBC的技术的扩展:ODBC允许你使用相似的接口来存取数据,而不管特定的后端(Back-end)数据存储技术。类似于ODBC,ADO要求对于每种特定的信息存储有一个不同的提供者。不同于ODBC只是对于数据库设计,ADO有一个高层的接口允许你从各种资源提取数据。只要你拥有对于特定数据源的提供者,你就可以使用ADO对象按照几乎相同的方式来读写数据。最后,ADO驱动适用于各种主要的关系数据库,你可以为文件型数据库以及平面文件找到驱动。
ADO.NET是ADO的最新进化版。ADO.NET修正了ADO原有的几个问题,扩展了它的能力,以及把它融入到.NET框架而不是像原来那样作为一个单独的插件(Add-on)。在这本书中,你将会广泛使用ADO.NET来存取关系数据。
XML解析器
有许多开源的或者商业的XML解析器。不同的解析器对于W3C的XML推荐有不同理解程度。和.NET共存的XML解析器甚至与微软最近释放的基于COM的XML解析器,msxml4.dll也有些许不同,但是它对于XML和XSLT的支持很符合W3C推荐。.NET框架广泛的使用XML框架做任何事情,从传递参数给SOAP到对象保留,所以,如果你还不熟悉XML和XSLT过程,在你读完这本书之后你就会了解了。
注意:你可以在这里找到XML标准:http://www.w3.org/XML/。
C#文件/流处理
.NET中新文件和流的处理的处理完全依赖于你在开始C#之前使用什么语言。例如,Java和C++的编程经验不会对.NET的输入/输出(I/O)操作的类和方法产生任何影响,但是经典VB开发者拥有很晦涩的并且极度过时的访问文件的方法。根据你怎么打开文件,有几种非常不同的向文件中写数据的命令。例如,如果你打开了一个文本文件,你可以使用Input函数来读数据,使用Print函数来把一些数据加到文件的后面。相应的,你可以使用Read #和Write #语句。相反的,如果你打开了相同的文件来进行二进制存取,你可以使用Get方法来读数据以及Put方法来写数据。
微软脚本运行时库(Microsoft Scripting Runtime Library)的微软版本包含FileSystemObject,以及一组代表文件和文件夹的对象。当你使用FileSystemObject代开文件时,它会返回一个TextStream目标让你可以用来读写文件。TextStream目标(正如它的名字指出的那样)只可以操作文本文件,而不是二进制或者是随机存取文件,但是它让文件存取非常直观。因为微软设计目标模型来操作像是VBScript和JScript的脚本语言,他们都只能使用变量(Variant),它不像类型目标或者是直接文件存取那样高效;然而,不管怎么样,微软都把它包含在VB6的释放版本中(VB6是一个对于包含到.NET框架的实验)。目标并不是VB运行时的一部分,但是你可以通过在VB中包含一个对于微软脚本运行时的引用来使用它们。如果你以前就是一个使用FileSystemObject来进行文件操作的ASP程序员,你会发现使用.NET方法也非常舒服。最大的不同就是FileSystemObject只能够读写文本文件,然而,C#的I/O能力让它也可以一样的处理二进制文件。
C#,就像是大部分现代语言一样,使用流来读写数据。流通常有两种形式——阅读器(Reader)和书写器(Writer)——但是一些流类(通过继承)提供了读和写的服务。流在.NET框架中无处不在。例如,.NET的System.IO的命名空间(Namespace)包含诸如StreamReader和StreamWriter,BufferedStream,FileStream,BinaryReader和 BinaryWriter,以及StringReader和 StringWriter,等等其他的类。
流的优点是,就像是ADO,他们提取能处理任何其他数据的过程。在选择了适当的Stream类之后,不同的流类之间的读写数据的方法都非常相似。例如,如果你在一个文件中打开FileStream,你可以使用它的Write方法来向文件中写字节。相似的,如果你在一个String对象中打开一个StringWriter流,你可以使用Write方法往字符串中写字符。你不再需要记住几种不同的方法来打开一个文件,相反的,你可以创建一个File对象并且使用它的Open方法来获得适当的Stream类型。对于大部分应用而言,高效的文件存取是非常重要的,网络应用程序也不例外。C#的文件操作支持,流控制加速,以及正则表达式的集成使得大部分I/O操作变得非常直接。
内存存储
不管你准备怎样长期存储数据,你还是很可能有需要把数据缓存到内存中。很明显,你这么做是因为从内存提取数据比从一个硬盘上的平面数据或者是数据库中提取数据快很多倍。相似的,为了最大化性能,经常需要缓存对象到内存中,这样你可以避免对于每次请求都创建和初始化对象。在以前的ASP版本中,你必须用C++或者Delphi写这样的对象。然而,你使用C#创建的对象对于缓存到网络服务器上非常安全。
C#,和ASP.NET一起,提供了很多服务器端缓存的选择。你可以缓存对象,页面,数据库查询结果,甚至是页面的一部分。你可以在一个预定的时间刷新数据,例如每15分钟或者是按照用户要求来做。当不在需要的时候,数据可以从缓存中清除。
你应该怎样包装数据?
不管你怎样存储数据——在内存中,在数据库中,或者是在文件中——你都需要包装数据,格式化它,并且把它发送到客户端来显示或者是在客户端脚本中使用。在网络应用程序中,数据的概念通常是让人疑惑的,因为程序员通常认为代码不同于数据。当然,当代码在执行时,确实是这样的,但是当你创建包含代码的客户端页面时,就不是这样了。在那个例子中,客户端代码是服务器端数据。它不需要在服务器上执行,所以直到代码到达浏览器,它更像是发送到客户端的文字。
在讨论各种类型的你可以发送到客户端浏览器的数据时,我有一个建议。把你发送到浏览器的数据想象成一个单独的文字串。忘记在这些字符中包含的类型数据。你最需要理解的事情是,对于大多数页面,你在发送一个字符串。原因是因为刚开始初级网络程序员非常疑惑什么在哪里发生,尤其是当处理客户端脚本时。因此,把所有的响应想象成字符串会简单些。
发送到客户端的HTML
通常,当写网络应用程序时,你需要发送HTML代码到客户端。即使是高级浏览器都只理解几种文件,例如HTML,CSS,文本,几种图像格式,XML文件,以及脚本。少数高级的浏览器只可以理解HTML和图像格式。大部分浏览器接受插件(Plug-in)来扩展他们可以使用的文件类型,其他的浏览器则不能。因此,你唯一可以依赖浏览器的事情就是他们可以解析和现实HTML 3.2。
注意:对于HTML3.2,我可能说错了,因此我自己没有测试所有的浏览器。然而,网络公司通常把HTML 3.2作为低端标准。
无论如何,你可能忘记发送你自己创建的文件格式到客户端。忘记发送几乎任何类型的对象。除非你使用一种浏览器可以解析的文件格式,否则它是不会被显示的。那并不总是坏的。旧版本的不支持JavaScript的浏览器会忽略掉脚本,如果你把它放在一个HTML注释标签中。例如, IE 3.x和网景 3.x会显示下面代码的警告框,其他浏览器则不会。
<!—“低层”浏览器会忽略的脚本-->
<script language="JavaScript">
alert(“这个浏览器可以运行JavaScript!”);
</script>
一些客户端的非浏览器类型,例如无线设备,使用一种叫做无线标记语言(WML)的特殊的XML类型。这些客户端也不使用JavaScript语言;相反,它们使用JavaScript的一种特殊变体,通常叫做WMLScript。
如果你足够幸运(或者是非常不走运,依赖于你自己的观点)在一个客户端浏览器被IT部门看管的局域网环境内,你可能不会在乎哪个客户端会认出哪种文件类型的讨论。然而,如果你在一个可以提供访问互联网,访问公司外客户端,访问远程合同工,或者是访问不经常使用浏览器的员工的公司工作,这个讨论就很相关了。
W3C’s 最终的HTML的推荐是4.01版本,但是最近,另一个XML的子集,叫做XHTML(可扩展的HTML),已经开始获得广泛应用。W3C使用模块来扩展XHTML,但是最简单的版本使用和HTML相同的标签,就是“结构良好的(Well-formed)”的方法。名词结构良好意味着文档遵循XML语法规则——除了别的之外,所有其实标签都有一个对应的结束标签,所有的属性值都是在引号中,所有的标签都是小写的。相应的,标准HTML能够包含像<p>或者是<br>的标签,属性值不需要在引号中除非他们包含嵌入的空格或者是其他分隔符,并且标签是大小写不敏感的。
通过对你的HTML文件做一些相对小的语法改变,你可以使用XML解析器来读文件的内容。那是主要的优点因为从HTML文件中提取内容是一个费时并且容易出错的过程。做出向XHTML的改变也很重要,你可以使用XSLT处理器来从你的HTML文件中提取数据并且对它进行转换。那为什么这很重要呢?下面是一个场景。
你加入了一个电子商务的网络应用程序来卖花。你有很多包含安排,价格以及邮寄信息的HTML文件。一些文件是对于来自数据库的动态信息的模板。应用程序对于想买花的人包含各种选择,包含安排投递,付款以及订单查询。市场部意识到,随着越来越多人开始使用无线设备,这有一个新的机会来提供让他们在移动中买花的机会。例如:
“呀,星期五晚上,你在离开办公室,你突然意识到这天是你妻子的生日。没问题:访问http://www.buyFlowersForYourWife.com/ 。他们会在30分钟内送到城市的任何地方!哇!太危险了!”
你被要求加入无线市场和商业能力到网站中。也许你想要做的第一件事就是让所有的页面动态化。在这中间,你想要从HTML文件中读物数据并且把它转换为WML数据。但是“正确的”答案是在这中间的某种东西。正确的答案是从一个你能够使用XML解析器阅读的表单中获得数据。最简单的步骤就是重新把数据格式化为XHTML。在这之后,你可以使用XSLT把数据转换成HTML,XHTML,WML,或者是用户喜欢的口味。当然,这将会花一些时间,但是最后的结果是当下次一个新用户出现时,只需要很少的工作,你将是第一个找到解决方案的人,并且所有人都会很高兴。
把XML数据发送到客户端
XML是一个有非常大的影响的但是简单的方法。方法就是:如果你把内容包装到HTML样式的标签,而不是使用像<table>和<h1>的标签,但是使用可以描述内容的标签名称,例如<person>,<employee>,<hotel>,<manufacturer>等等,该怎么办呢?再进一步:一些HTML标签是包含其它标签的块标签。如果你想要使用这种能力而不仅仅是嵌套标签,同时,标签和它们的包含器要被认为是父子关系,该怎么办?简单的说,那就是XML。不同是HTML是一个格式化语言,然而XML是数据描述语言。
XML更罗嗦,但是当你想要系统的提取信息时,它更方便。例如,考虑在HTML文件中的一个表格,如果你想要提取列头和值,你需要解析文件来查找<td>和</td>字符。那本身不难,但是当<td>标签包含其他的HTML标记,这就很难了。比较起来,使用DOM来提取相同的信息很容易。DOM让你使用XPath查询来找到内容——标签的属性或者是文档的“结点(Node)”——并且决定标签和它的孩子,兄弟,或者是父亲节点的关系。DOM也让你使用XSLT来把文档从一种转换到另一种。
SOAP请求/响应
从意识到XML是一个非常强壮的数据描述语言到意识到你可以使用XML描述对象,方法,以及参数是一小步。事实上,这个方法如此简单,所以几乎每个主要的数据库以及商业工具提供者在微软发布SOAP两年之内,都开始采用它。如果你知道一些提供者的竞争关系,那么你就会了解那有多重要。
如果你可以在XML中坚持使用对象和数据,并且使用它描述方法调用以及相关参数,那么你就可以把XML当作一个传输机制来在HTTP中使用远程方法调用来避免在使用二进制数据实现同样功能时会遇到的问题。大部分防火墙会屏蔽二进制数据因为它会包含恶意代码,但是它们允许文字通过。使用平面文字SOAP包,你可以把二进制的表达传输过防火墙。
理解SOAP是一种标准的XML格式来进行远程调用和返回值对你而言是很重要的。除了说它是标准,SOAP根本就没有什么特别的。事实上,在你的应用中,你可以绕开SOAP并且使用一个定制的,更现代的版本——但是如果你那么做,你就不会知道一些.NET的内置优点。
当你创建网络服务工程,.NET框架会接管解析SOAP格式的请求并且以SOAP格式来返回值。
定制数据流
有时,你会有不是适用于标准包的数据处理需求。例如,你可能因为性能原因,你的应用程序必须维护一个一直开放的通道来和服务器通讯。C#有比经典ASP更好的内置的网络通讯存储机制。事实上,你可以使用C#不费太大力气写一个定制的HTTP服务器。System.Net类包含TCPClient,TCPListener以及UDPClient类来封装窗口套接口(Windows Socket)。使用这些类,你可以使用高层的套接口接口来实现定制的数据流应用程序。如果你需要低层的存取,System.Net.Sockets类提供了基本的服务来创建互联网连接。
--------------------编程问答-------------------- 怎么没有了!!!!期待中 --------------------编程问答-------------------- 期待PDF!!!!
牛人啊。。。。。。。
有个小建议,能把有些图片处理下吗
很影响整体感觉。。 --------------------编程问答-------------------- 上面的人们已经说出来了大家的心声,楼主固然很强,这是毋庸置疑的,不过我们一些读者们还是比较喜欢PDF文档形式的 --------------------编程问答-------------------- 顶!!! --------------------编程问答-------------------- --------------------编程问答-------------------- 太牛了。。。。。。。。 --------------------编程问答-------------------- 真全啊!!!借用啦!
补充:.NET技术 , ASP.NET




